









Imagine this: Black Friday, peak sales. The monitoring dashboard flashes red—credit decision latency, which normally takes fractions of a second, suddenly stretches to two seconds. Shoppers abandon carts, merchants lose revenue, and it becomes clear that the ten‑year‑old ASP.NET MVC monolith has simply hit its ceiling.
This is the reality of 2026, where the average enterprise already uses more than 890 applications. We live in an era of extreme fragmentation, where the lack of integration costs the average business about $12.9 million annually. But the scariest part isn’t that. The scariest part is that 90% of attempts to completely rewrite legacy architecture (the “rip-and-replace” strategy) fail on the first try.
Why? Because most teams start writing new cloud code without truly understanding how the old system works. They try to replace the airplane engine mid-flight without even having its schematics. The total volume of technical debt in the U.S. has reached a staggering $2.41 trillion, with most of it concealed in the “blind spots” of enterprise application integration layers. This isn’t just a technical exercise. In our case, such modernization allowed the client to expect a 19% increase in annual revenue (+16% already achieved during implementation) thanks to faster checkout and system stability. We demonstrated that a well-structured six-week discovery sprint can transform a legacy monolith into a profitable asset rather than merely a financial burden.
In this article, I want to share a real case from our Devox Software team, where we modernized a legacy BNPL platform by migrating it to AWS microservices with response times under 300 ms. We did it with absolutely zero downtime. Our key insight is simple but fundamental: the success of enterprise integration layer modernization (APIs, ESBs, and EDAs) doesn’t depend on the choice of cloud provider but on precise dependency mapping — an accurate mapping of dependencies conducted before you delete the first line of legacy code.
Blind Spot of Monoliths: Why Integrations Break
In the modern enterprise environment, the integration layer is the nervous system of the business. The problem is that more than 71% of systems remain non-integrated, creating “data silos” within a fragmented enterprise architecture integration layer. In our BNPL case, we faced a typical “blind spot” where critical checkout logic intertwined with reporting and scoring in a single IIS pool.
The main reason integrations break under load is a lack of visibility. We discovered:
- Shadow APIs: Undocumented calls developers had created over the years for “quick fixes.” They live outside the enterprise service bus (ESB) and become the first points of failure.
- Zombie APIs: Legacy integrations that should have been shut down but still consume database resources and block request flows.
During peak sales, these hidden connections created a “domino effect.” Synchronous calls to three credit bureaus for fraud scoring triggered timeouts that blocked the entire request stream. Modernization fails because teams build new systems on top of the “digital debris” of the old one without a clear dependency map, even when evaluating enterprise service bus alternatives.
Currently, the situation in the U.S. enterprise sector has reached a critical point: the average large enterprise operates 897 applications (50 more than two years ago), but 71% of them remain non-integrated. This extreme fragmentation creates massive data silos that force staff into manual work and cost companies an average of $12.9 million in operational losses annually. The absence of a clear enterprise integration roadmap and precise dependency mapping turns systems into “black holes,” where productivity disappears.
Evidence-Based Decision Making
I often see companies trying to overcome this lack of transparency through “legacy archaeology,” manual code analysis that exhausts talent and leads to attrition. In a world where technical debt in the U.S. alone has reached $2.41 trillion, we cannot afford to act blindly.
At Devox Software, we changed the rules of the game. Before discussing migration budgets or choosing between API Gateway and EventBridge, we follow a structured enterprise integration roadmap, starting with a full technical audit using our AI Solution Accelerator™. This gave us:
- Precise coordinates of architectural choke points: We clearly identified where underwriting logic intersected with the transaction database, creating latency.
- ROI-Friendly Modernization: With the map in hand, we prioritized migrating only the parts that truly slowed down the business.
For our BNPL client, this audit showed that a full “rip-and-replace” wasn’t necessary. We had evidence that the credit-decision engine required immediate decomposition. We replaced assumptions with facts, and that became the first step toward zero downtime. It’s important to understand: we’re building the integration layer not only for mobile apps and web portals but as part of a scalable API-first enterprise architecture. The new consumers of your APIs are AI agents. Our mapping allows us to prepare the architecture for implementing an AI Gateway. This is important for adding context and managing tokens; if you don’t have accurate mapping of dependencies, you can’t securely allow your corporate LLM models to access internal data without breaking security rules.
Establishing Baseline Parity
The greatest fear during integration‑layer modernization is the situation where the new cloud system works, but works “slightly differently” than the old one. In FinTech, that “slight” difference can cost millions. If the new credit scoring API returns a result 5 milliseconds later or uses a different rounding precision, it can break downstream reporting processes or cause discrepancies in merchant settlements.
Thanks to precise dependency mapping conducted at the start, we didn’t just see the connections; we captured the “ground truth” (the single source of truth).
In our BNPL case, we used the dependency map to establish baseline parity before deploying the first microservice on AWS. We captured:
- Reference input and output data: Every request to credit bureaus and every response from the monolith was documented as the “gold standard.”
- Behavior under load: We knew how the legacy bus behaved when the request queue hit peak levels.
With this baseline, we could compare the new system’s behavior against the old one in real time. We didn’t just migrate code; we migrated logic with the guarantee that no business outcome would change without our knowledge. Baseline parity is your insurance against “silent errors” that usually surface months after release.
For our BNPL client, this stage was a matter of survival in the regulatory field. New CFPB (Consumer Financial Protection Bureau) directives require FinTech companies to maintain detailed audit trails at the field level for every credit decision. The legacy system stored only the final status flag, leaving it vulnerable to fines. Using the dependency map, we implemented immutable JSON snapshots of every decision step with SHA hashing. We captured baseline behavior not just for code stability but to make the platform audit-ready, even before it fully migrated to the cloud.
Safe System Decomposition into Autonomous “Slices” (Micro-slicing)
With precise coordinates of all dependencies, we avoided the risky “rip-and-replace” approach. Instead, we applied the micro-slicing strategy.
Imagine the monolith as a tangled knot of wires. Instead of trying to untangle it all, we surgically extracted individual “slices,” vertical domains containing their logic and state.
For our BNPL platform, we chose the most painful slice, the credit-decision engine.
- Isolation: We wrapped this slice in a service layer, allowing it to function as an independent module inside the monolith.
- Cloud migration: With precise knowledge of the data this module required, we rewrote it in pure ASP.NET Core and deployed it in AWS ECS Fargate containers.
- Asynchronicity: We replaced blocking synchronous calls to credit bureaus with an event-driven model (EDA) using Amazon SQS queues.
This decomposition enabled us to gradually modernize the system. While reporting and email notifications still “lived” in the old monolith, the heart of the system, credit scoring, was already running in the cloud with response times under 300 ms. Using micro-slices eliminates the need for long “maintenance windows.” You simply move business value from the old system to the new one gradually, without stopping the business.
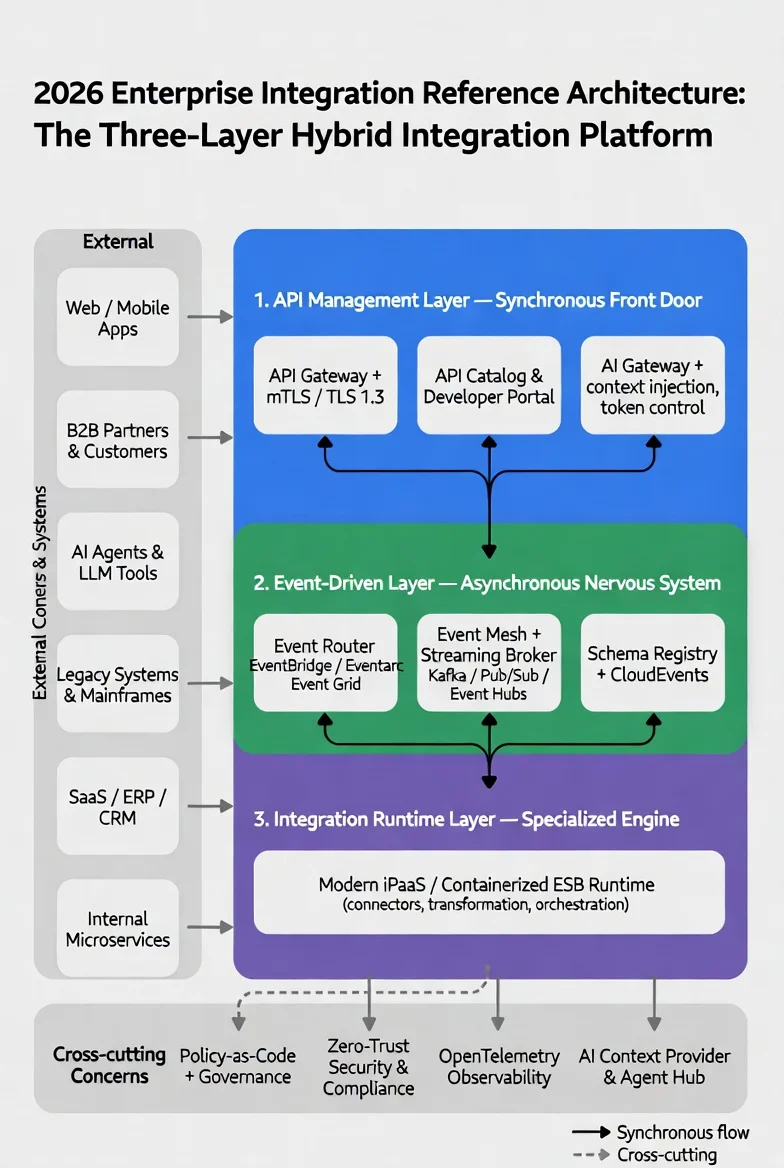
Breaking down a monolith goes beyond microservices; it requires a shift to a three-layer hybrid integration platform. Flows were separated into:
- the API Management Layer for instant UI responses,
- the Event-Driven Layer for asynchronous scoring via SQS,
- and the Integration Runtime for heavy orchestration.
Our six-week discovery sprint allowed us to surgically isolate the credit engine. To solve the classic “dual write” problem, when data in the database and events in the broker can desynchronize due to network failure, we implemented the Transactional Outbox pattern. This guaranteed that writes to PostgreSQL and messages to the SQS queue were always in a state of absolute integrity. It allowed us to “cut out” a piece of the monolith without losing a single transaction.
Building Comprehensive Regression Safety Nets
The biggest nightmare during a large‑scale migration isn’t server crashes. A crashed server is easy to spot and restart. The real threat in high‑tech FinTech is the “silent failure.” This is when services appear to be working, but due to a subtle discrepancy in an API contract or a change in data processing logic, transactions start getting lost — or worse, credit limits are calculated incorrectly.
Decomposing a system into micro-slices and migrating it “on the fly” inevitably leads to the most dangerous phase, the hybrid state. At this point, part of the logic already runs in new cloud microservices on AWS, while another part, such as the reporting module or the old database, remains in the legacy system. If you rely solely on manual testing, you’re essentially signing up for a “parade of incidents” after every release.
To guarantee our BNPL platform clients the promised zero downtime, we introduced the concept of uncompromising regression safety nets. And this phase is where our investment in precise dependency mapping paid off enormously.
Because we carefully analyzed and recorded every possible way the old system worked during the AI audit with our accelerator, we understood exactly how the system should behave for any request in its normal state. This allowed us to automatically generate E2E tests: We transformed the dependency map into a set of end-to-end scenarios. We didn’t just test the new code in isolation; we tested the interaction of new AWS ECS Fargate microservices with old monolith components.
We captured baseline behavior not just for code stability but to make the platform audit-ready, even before it fully migrated to the cloud. Our safety nets, built on the precise dependency map, became not only a quality tool but also an architectural lever. They allowed the development team to confidently work with a hybrid system, where the old monolith and new AWS services ran simultaneously. Automated tests covered every integration, eliminating the risk of human error. This enabled us to maintain a pace of four sprints to fully modernize the critical core without losing control over the integrity of financial operations.
- Validate contracts in real time: Every call between the “sliced-off” credit scoring module and the remaining monolith was checked against the schema. If a developer accidentally changed a data type in an SQS message, our safety net caught it at the CI/CD stage, blocking the build.
- Eliminate the “human factor”: Automated safety nets allow less experienced engineers to confidently work with complex systems, knowing that automation won’t let them accidentally break the critical integration layer.
Result: For our BNPL project, the outcome was fundamental: we achieved an audit-ready system. Every migration step was verified by thousands of background tests. This provided developers with speed and the business with peace of mind. We knew for certain: the new cloud architecture worked identically than the old one, and not a single client’s cent would be lost in the “dark corners” of the hybrid infrastructure.
Incremental Traffic Routing Without Business Downtime
When the “safety nets” are in place, the moment of truth arrives, switching to real traffic. For a large enterprise, the “big-bang” strategy is an unjustified risk. In our BNPL case, we leveraged the power of modern API gateways and the flexibility of AWS ECS Fargate to implement incremental routing.
Instead of sending all users to the new microservices at once, we adopted blue-green deployment. Using automated pipelines, we deployed a new set of containers in parallel with the existing ones, and the cloud infrastructure smoothly switched target groups. This allowed us to direct only 1% of traffic initially to the updated decision engine.
We didn’t just switch traffic; we managed it through GitHub Actions and Terraform IaC. The process looked like this: the pipeline deployed the “blue” set of containers in Fargate, and AWS X-Ray monitoring tools confirmed the success of each data hop in the new network. Only after X-Ray recorded zero errors and sub-300 ms latency did we fully merge the old traffic. Merchants never noticed the handoff; for them, the system simply started working instantly.
Thanks to deep monitoring and tracing via AWS X-Ray, we saw every request hop in real time. We tracked how messages passed through SQS queues and whether there were any latency anomalies. Only after confirming that latency consistently stayed below 300 ms even under load did we gradually increase the share of traffic. Merchants and customers were unaware that the platform had undergone a complete technological transformation. This approach transforms deployment from a source of stress into a routine business operation aligned with modern enterprise integration, where zero downtime becomes the standard.
Continuous Synchronization and Data Integrity (CDC)
But traffic routing is only part of the success. The real challenge lies in data integrity. In distributed architectures, one of the most painful problems is dual write, when, due to a network failure, data in the database and events in the message broker become desynchronized. Such an outcome is unacceptable in a financial platform that requires legal validation for every transaction.
For our BNPL platform, we implemented Change Data Capture (CDC). This allowed us to keep the legacy monolith database and new cloud storage in perfect balance throughout the migration period.
- Audit-Ready Data Lineage: We recorded every engine decision, every response from credit bureaus, and the final verdict, along with immutable JSON snapshots. This ensured full transparency for financial audits and compliance with new regulatory requirements.
- Eliminating reconciliation delays: Heavy nightly data reconciliation processes, which previously took more than 90 minutes and often slowed down business operations in the morning, were decomposed into lightweight AWS Lambda steps. Now the finance team receives verified reports in 9 minutes instead of an hour and a half.
- Hybrid stability: Using DynamoDB to store session tokens allowed us to instantly confirm credit approvals in the user interface while core financial records synchronized in the background.
Thanks to the CDC, we didn’t just migrate data; we created a new quality of financial reporting. We eliminated the risk of discrepancies between systems, guaranteeing that the “truth” in the new cloud architecture always matched the “truth” in the legacy system until its complete shutdown. We reduced the nightly reconciliation window, which previously took 90 minutes and often delayed settlements with banks, to 9 minutes. The finance team now starts the day with a “green” dashboard.
Conclusion
Modernizing legacy integration layers isn’t about replacing one technology with another. It’s about transforming your “nervous system” from a brake into a business accelerator.
In our BNPL example, we found that using APIs, ESB, and EDA together with careful tracking of dependencies achieved results that once felt out of reach: reducing delays by six times, cutting cloud costs by a third, and being fully prepared for everything, all of this, without a single minute of downtime.
My key insight for colleagues: don’t fear your legacy. Start by eliminating the “blind spots,” use evidence instead of assumptions, and you’ll be able to modernize even the most complex system while preserving business continuity and customer trust.
Frequently Asked Questions
-
What is modern enterprise integration, and why is it important?
Modern corporate integration is no longer about simply “making two applications get along.” In the past, we relied on heavy, unwieldy systems, where even the smallest change required months of approvals and carried the risk of breaking everything at once. Today, it’s a shift toward a flexible, breathing ecosystem that typically consists of three layers, where event-driven architecture enterprise plays a key role as the nervous system for real-time event transmission alongside APIs and integration engines. In essence, we’re untangling a knot of wires and building a transparent, modern backbone instead.
Why is this transformation so critical right now? Because the old approaches simply can’t keep pace with modern business. Isolated systems lead to developer burnout from constant firefighting, customer delays, and a loss of agility. Modern integration gives you back control and peace of mind. It creates a solid foundation that enables innovation, for example, safely connecting autonomous AI agents without fear that a single misstep will bring down your company’s critical processes. It’s the transformation of your IT landscape from technical debt into a primary driver of growth.
-
How do APIs, ESB, and event-driven architectures compare?
Imagine such a scenario as the evolution of communication within your business. The outdated enterprise service bus is like an over-controlling manager: it tries to orchestrate every process centrally, highlighting the clear advantages in a Microservices vs. ESB comparison, where microservices provide agility and resilience under peak loads.. An API serves as a direct, fast phone line, making it the ideal tool for synchronous tasks that require immediate responses when a user clicks a button on a website. In contrast, event-driven APIs operate like a modern “nervous system”: one service signals that an event occurred, and all other independent modules instantly respond in the background without blocking each other’s work.
The secret of successful modernization lies in the fact that you don’t need to fanatically choose just one; modern enterprise solutions are always hybrid. The biggest mistake I often see is the attempt to replace ESB with microservices without a defined ESB modernization strategy, which only creates more expensive chaos. True engineering mastery is about assigning the right roles: keeping APIs as the “front doors,” handing off heavy asynchronous processes to EDA, and isolating what remains of the monolith. For this puzzle to fit perfectly and start generating revenue, you need a precise audit of your unique ecosystem, and my team is ready to help you design this transition plan without risk to current operations.
-
How can enterprises modernize legacy integration layers?
Safe modernization of outdated integration layers doesn’t begin with writing new code; it starts with creating absolute transparency. Instead of the risky replacement of the entire system at once (the so-called “big-bang” approach), successful companies begin with a phase of deep audit and inventory of existing integrations, contracts, and SLAs. Following best practices for modern enterprise integration, we map all connections first and then gradually move specific processes from the central ESB using the ‘Strangler’ pattern. This allows us to update critical business nodes without risking a shutdown of the entire system.
The key to achieving zero downtime lies in properly synchronizing the hybrid state. Using patterns such as Transactional Outbox and CDC ensures reliable event publication and solves the problem of data desynchronization between the old database and new cloud services. Modernization is a managed process that should deliver value at every stage. If you’re searching for a reliable partner to help untangle your technical debt and build a step-by-step migration strategy without stress for the business, our team is ready to conduct a deep audit of your infrastructure.
-
What are the best practices for API-first enterprise architecture?
Building an effective API-first architecture requires moving from chaotic interface creation to strict “contract-first” standards and robust API management for enterprises to ensure security, scalability, and compliance.. The best practice is to use OpenAPI specifications for synchronous requests and AsyncAPI for event streams, even before writing the first line of code. The enterprise’s single “front door” is the modern API Gateway, which centrally manages quotas, versioning, and security policies like mTLS and TLS 1.3. In addition, governance should no longer slow down development: instead of quarterly committees, leading teams use automated catalogs and a policy-as-code approach.
Security and testing must also be embedded in the very DNA of the architecture. Contract testing of invariants and backward compatibility becomes a mandatory standard; without it, large-scale migrations turn into nightly parades of incidents. It’s also important to prepare the architecture for new challenges, such as supporting integration with AI agents through specialized AI gateways for access and token control. We know how difficult it is to implement these standards across the entire enterprise, but robust API gateway enterprise solutions provide the framework to scale securely and efficiently. Our architects will help you set up development processes and deploy a reliable API management platform so that your services become scalable, secure, and future-ready.
-
How do event-driven architectures improve enterprise integration?
A real-time event processing enterprise approach lets systems communicate asynchronously, eliminating bottlenecks and increasing responsiveness. Instead of systems waiting by relying on each other and creating “bottlenecks,” EDA enables services to react to events in real time through message brokers and streaming platforms. This radically increases system reliability and enables scaling to handle tens of billions of events per day without loss of performance.
Adopting event-driven integration solutions drives faster time-to-market and reduces maintenance costs for complex enterprise integrations. In addition, implementing standardized formats such as CloudEvents and Schema Registry guarantees data consistency across dozens of independent teams. However, transitioning to EDA requires a profound understanding of patterns such as idempotency and compensating transactions. We have practical experience deploying such systems and will gladly design a reliable event backbone for you that makes your business truly reactive and resilient under load.
-
What are the common challenges when modernizing integration layers?
One of the greatest challenges during modernization is overcoming “blind spots,” thousands of undocumented connections, and “shadow” APIs that have accumulated over the years in outdated monoliths. Without a precise understanding of these dependencies, any attempt to update the system leads to cascading failures and large-scale production incidents. Another critical problem is the danger of “dual writes,” when, due to a network failure, data in the primary database and events in the message broker become desynchronized.
In addition, companies often face chaotic API sprawl without proper governance and schema incompatibility issues when transitioning to asynchronous streams. To fix these issues, you need to have strict rules for contracts and monitor everything from start to finish using OpenTelemetry. Guiding a system through these pitfalls alone can be extremely difficult. Contact us, and we will help identify your architectural risks even before migration begins, ensuring a smooth and safe transition.
-
How to evaluate iPaaS or modern integration platforms for enterprises?
When choosing a modern integration platform, you should avoid searching for “one universal tool” and instead evaluate the solution’s ability to operate within a composable architecture. The ideal platform should easily combine management of synchronous APIs, routing of asynchronous events, and specialized engines for orchestration and data transformation within a modern integration platform as a service (iPaaS). Pay particular attention to the level of managed services, which reduce the burden on your infrastructure team, as well as built-in support for modern security standards such as mTLS and policy-as-code.
It’s also critically important to analyze pricing transparency, make sure the payment model matches your actual traffic volumes and won’t lead to unexpected overspending. Considering current trends, the platform must support integration with AI agents and open telemetry standards for deep monitoring. Choosing the right stack is a strategic decision for years to come. We are ready to analyze your business requirements and select the optimal combination of platforms that will deliver maximum ROI and performance.


