
















Every day, technology professionals have to deal with the hidden hazards of legacy systems. Otherwise, they will quietly slow down performance. Refactoring legacy code is one of them.
For instance, think about how you would have to start a new loyalty program to make money. Adding a new field to a user profile, like loyaltyPoints, is all it is on paper. But when your team looks at the codebase, they find 50,000 search results spread out over old services and migration efforts that aren’t finished yet.
Some pieces are undocumented legacy code Java SOAP services that are still running important login flows. Some are GraphQL resolvers that were never finished and were left behind years ago. No one knows which modules are safe to touch without damaging important processes.
Writing new code isn’t the challenge; understanding the current system well enough to make changes without stopping business is. Every update is a risk to client satisfaction, uptime, and income if you don’t have the necessary tools.
That’s why AI-powered tools need to do more than just programming. They need to show the whole repository, map dependencies, and give actionable insights. This gives tech leaders control over complicated systems while lowering risk, speeding up delivery, and raising ROI.
Why Do Most AI-Powered Tools Fail at Legacy Code?
More than 47% of developers are currently using AI-powered tools in their work. The amount will surely grow. But if AI-powered tools are so effective at digging into legacy code advancements, why does everybody not use them?
There is a problem: AI-powered tools have basic constraints that make them not good for complicated systems. This problem incorporates 4 main issues that we’re going to describe now.
- The Wall of the Context Window: Standard AI assistants can only “see” a few thousand tokens at once. Simply put, they can read, at least, page by page in a 1,000-page book. As a result, important information gets lost as the model loses sight of the overall legacy code picture. The same thing as ChatGPT “forgets” about some part of the prompt if it’s overloaded with details.
- Common Pattern Disease: Most models learn from open-source code in common repositories. That’s why in many cases they offer “textbook solutions” that are far from real-life environments. For the same reason, untrained AI-powered tools can be helpless with your internal legacy code documents. The model had simply never seen it before.
- Old Training Data: Off-the-shelf AI-powered assistants suggest old APIs or method names that need legacy code refactoring. It slows down your job instead of speeding it up, wasting time on evaluating AI suggestions twice before application.
- Too Many Tools: When AI assistants are not customized, teams start to fill up the gaps in one tool by adding other plugins: one for testing, one for security, and one for infrastructure routines. It accumulates stress and unfocuses, slowing down development.
The good news is that all these pitfalls can be easily covered with modern custom AI-powered tools. By tuning them, you can get a comprehensive assistant across many phases of SDLC. Let’s consider what you should include in it.
Features Developers Really Need in AI-Powered Assistants
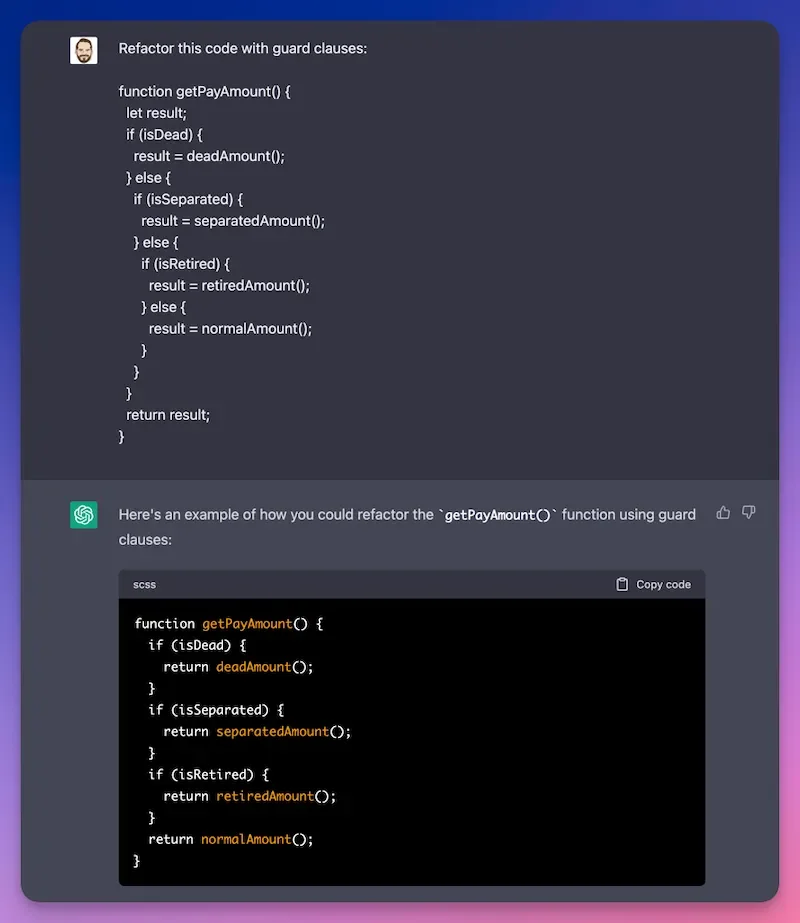
30% of developers who are applying AI in SDLC make it for codebase reviews. The problem is to make AI-powered tools. The difference between helpful and harmful AI comes down to understanding vs. prediction. Instead of guessing and assuming, trained AI analyzes and indexes all legacy code repositories to see the full picture of how components interact to output recommendations.
Full Repository Context
The AI tool is supposed to index all of the legacy code, not just the current file. If it’s done right, you can ask deep, system-level questions like “Which services consume Order.totalAmount after checkout?” and receive every related result immediately. AI highlights as follows:
- Places in the code where the value is kept,
- Prepared data for reporting,
- Linked edge cases are checked throughout unit tests,
- Even the connected microservices that could break if the field changes.
As a result, the workflow is much simplified and accelerated. You can see the whole system dependencies automatically, and you don’t need to pick them by hand. For instance, if you want to add a new field, a simple autocomplete advises updating the DTO and the database schema at once. Very convenient.
Architectural Pattern Recognition
Every organization has unique legacy coding patterns. A useful AI assistant reads, learns, and respects your architecture, not generic open-source conventions from a textbook. What are these patterns? Usually, these include the following:
- Custom authentication wrapper type,
- Internal data access layer structure,
- Folder structures, etc.
An AI-powered assistant identifies these relationships to incorporate them into its output, so they can’t break the system logic.
Cross-Service Dependency Mapping
Modern apps are complex, containing hundreds of different repositories and services. AI assistants easily map these connections without manual guidance. Moreover, they can track changes and find faulty lines or services before they go live.
As a result, AI-powered assistants lend a helping hand to developers in many aspects.
How to Find an Appropriate AI Tool
Since not all AI-powered tools are equally good for legacy code, let’s consider the best approach in assessing their use cases and benefits. Some promos offer software, “trained on billions of lines,” but this is another marketing trick. Instead, we offer a simple but helpful five-finger test.
- Cross-Repo Search: Ask the helper to find every write to user.preferences.theme across codebases. The result will show whether this tool can overview the entire system at once.
- Impact Analysis: Show everything affected by changing it from a string to an enum.
- Change Generation: Generate a pull request (PR) that updates all dependencies and check the results.
- Test Identification: List test changes and explain why. You then assess the reasoning.
- Performance Check: Measure response time and determine if any hallucinations occurred in the process.
If the AI Tool fails here, it won’t handle real-world work, so it’s better to try another from the start. And conversely, if it delivers rational answers, give it a try. Of course, it won’t be a 100% guarantee that the AI tool is error-free; however, the chances are higher.
To sum up, the following capabilities differ a good AI tool from a mediocre one:
- Full Codebase Indexing: It means the search must crawl and process the entire repository, no matter the size and complexity.
- Semantic Understanding: AI must comprehend syntax highlighting, architectural patterns, custom framework cases, and trace data model propagation.
- Dependency Analysis: The best AI tools map service relationships for easy legacy code refactoring. Moreover, integration with CI/CD pipelines helps catch issues before they reach production.
This method generally shows that one or two specialized tools can meet most demands, while the others just duplicate features and use up resources.
How to Tune Performance and Resource Usage with AI Tools?
More AI assistants don’t mean more productivity. Each tool spawns its indexers and inference calls, slowing everything down. That’s why any switch between tools should be carefully planned.
Engineers who work with big repositories already deal with sluggish compilation, feedback loops, and extensive test suites. Adding overlapping additional layers makes an already weak foundation even weaker. However, we still can (and should) optimize performance at our best. Let’s consider the best ways to tune performance and resource usage via AI tools.
- Limit the number of tools used simultaneously to minimize the computational workload within the codebases.
- To get clean performance stats, start with just your IDE and no add-ons. Then add the AI tools one by one.
- To begin, consider incorporating tools that effectively save time, and consider removing those that are more costly than beneficial.
- Provide simple features, such as linting, formatting, syntax completion, and others, locally to avoid latency. And heavy analysis tasks like semantic search and cross-service impact analysis, in their turn, go after.
This way, one or two specialized tools cover most needs, without any additional complexities.
How to Implement AI Tools into Workflows, Right?
Here is the 90-day implementation plan to meet the basic requirements and patch insufficiencies that might arise in the process.
- Lay the Foundation: Establish metrics and gather requirements: measure build times, search speed, PR completion rates, etc. Developers of large systems spend too much time troubleshooting and navigating instead of adding new features. So, prepare to minimize this overload.
- Validate: Turn off all unnecessary extensions. Find out which plugins are affecting your development environment by watching the connections between CPU usage, productivity, and overall performance.
- Scale: Deploy one assistant to the most painful area (search, legacy code review). Cross-file search, dependency mapping, and refactor suggestions are the same tasks that were used to test it previously. Ensure that the tool supports multiple repositories.
- Measure and Repeat: Did the times for searches go better? Is background indexing making test runs go faster? Teams with repository-aware assistants generally perceive big boosts in productivity, but these claims can be backed up with data. If the data demonstrates real progress, use it more. If not, look for other options.
During implementation, avoid anecdotal evidence. Let commit throughput, build performance, and context-switch frequency decide what tools you keep.
Helpful Tips and Strategies
Integration that works well doesn’t make new workflows. It works with the ones that are already there, so the developers feel empowered, not burdened. Here are some tips and tricks of the trade to simplify your AI-powered tool integration.
Watch Reper Points
CI/CD integration: Catch breaking changes before they merge. AI-powered tools can automatically create tests, stop builds from violating contracts further down the line, and show errors before they go into production. Newer technologies connect directly to Jenkins, GitHub Actions, and cloud runs, so problems are found before they snowball.
Pull request enhancement: Inline analysis during review. Context-aware reviews point out policy violations and recommend changes in the legacy code based on the entire repository’s insights. You don’t have to search through files to see how changes will affect things; you get analysis right in the review interface.
Chatbot answers: Context delivered via Slack or Teams. This gives you responses without interrupting your main communication.
Avoiding Gaps in Integration
The truth: anything that stops keystrokes for “real-time” analysis, sends out too many notifications, or needs manual context uploads will eventually be turned off. So when suggestion windows get in the way of debugging, the productivity flies away.
The answer? Partially, asynchronous processing is. Heavy dependence analysis operates on servers and sends back results when they are ready. So you can only see review comments when tests pass. Instead, try logging summaries into chat channels so you can read them when necessary. Integrations must not break up a developer’s flow; they must provide context without ripping off focus.
A Word for Security
One of the major concerns of mass usage of AI-powered solutions in SDLC is compliance and security. Unmanaged AI assistants in legacy coding introduce real risk. While developing our AI Solution Accelerator™ pipeline, we’ve drawn together 3 major rules of safe usage of AI:
- Code keeps inside the limits of security: No calls to external APIs unless they are on a whitelist.
- Keeping an audit trail: Every modification is signed, dated, and can still be found in the current source control logs.
- Integration of access control: Map the routes of the repository to SSO groups and use existing policy engines to enforce permissions.
These practices support compliance with SOC 2 and ISO 27001, so you can fully rely on them.
What Metrics Are Crucial to Monitor?
As a cherry on top, consider these metrics to ensure the timely and relevant outcomes:
- Context Acquisition Time: The amount of time developers invest in reading legacy code, identifying connections, and gaining a deeper understanding before making changes. Good tools cut down time expenses by generally 30%.
- Cross-Service Regression Prevention: The percentage of releases that didn’t need any hotfixes because they missed dependencies. Before deployment, context-aware tools show hidden connections instead of after-production alarms.
- Feature Delivery Velocity: The number of stories each developer finishes in a sprint. Teams that utilize repository-understanding technologies say they deliver 20–50% faster since they don’t have to pause to answer “how does this work?” inquiries.
- Flow for Developers Duration: Time spent solving problems without interruption vs. time spent managing the environment. Longer flow is closely linked to job satisfaction and keeping employees.
- Keep an eye on these numbers every week, and don’t pay attention to stats that don’t matter, like how many suggestions were accepted. Not the quantity of people who use the product, but how well developers do their jobs, affects business outcomes.
But remember, the key to success is to focus on understanding rather than predicting, use hard measurements to show impact, and only keep the technologies that speed things up and slow down regressions.
The Bottom Line
Despite some minuses, AI turns out to be a valuable tool for understanding and legacy code refactoring. With the variety of services and solution accelerators in the market, you can find the one that precisely suits your needs. You only need to pick an AI that can do more than just guess; it should also know how your system works.
Use metrics to show value. Combine where developers already live. Keep only the assistants that speed things up and cut down on regressions, and get rid of the rest. These are our biggest recommendations as a company that streamlines development for our clients at large.
If you need a specialized approach in AI for legacy systems, book a consultation. We’ll find the way to make your legacy code sound and running again with ease.
Frequently Asked Questions
-
Can we have more than one AI-powered tool for legacy code refactoring?
Yes, there are many various solutions. including a virtual assistant solution accelerator. But start with one that gives you full-repo context. Add other people only if they bring something unique and useful.
-
How do we keep generic patterns from sneaking in?
Use internal examples for retraining, employ linters and policies to enforce conventions, and implement PR checks as gatekeeping measures.
-
When should we connect to CI/CD?
As soon as a pilot looks promising. CI catches surface breakages before they merge, which is when fixes are least expensive.
-
Should we opt for custom or off-the-shelf AI-powered solutions for refactoring legacy code?
If you need a tailored solution for long-term profits, then build. Off-the-shelf tools are easier to get, but their use cases are narrower.


