









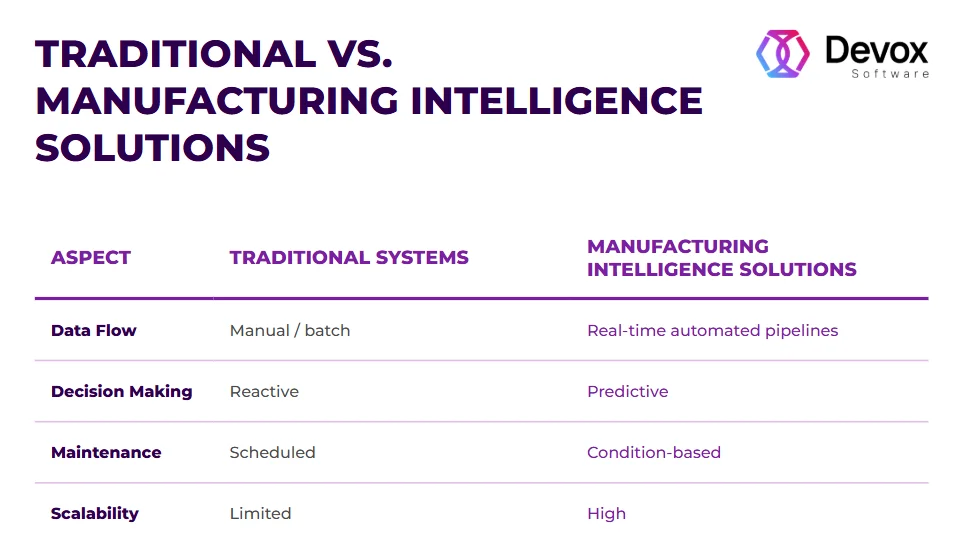
Data pipelines describe how raw data flows through production into decision centers for businesses. If everything is done right, thanks to automated pipelines, companies collect, clean, integrate, and analyze vast amounts of information from various sources.
So, how to truly leverage them? At Devox Software, we’ve worked with manufacturers, among others, to prepare their tech for an Industry 4.0 state. In one recent case, the complexity even rose: a mid-size manufacturer struggled across five plants despite available sensor data. So we chanced to see that the visibility wasn’t the issue. That’s why we’ve prepared this article to clarify some points. Let’s get underway.
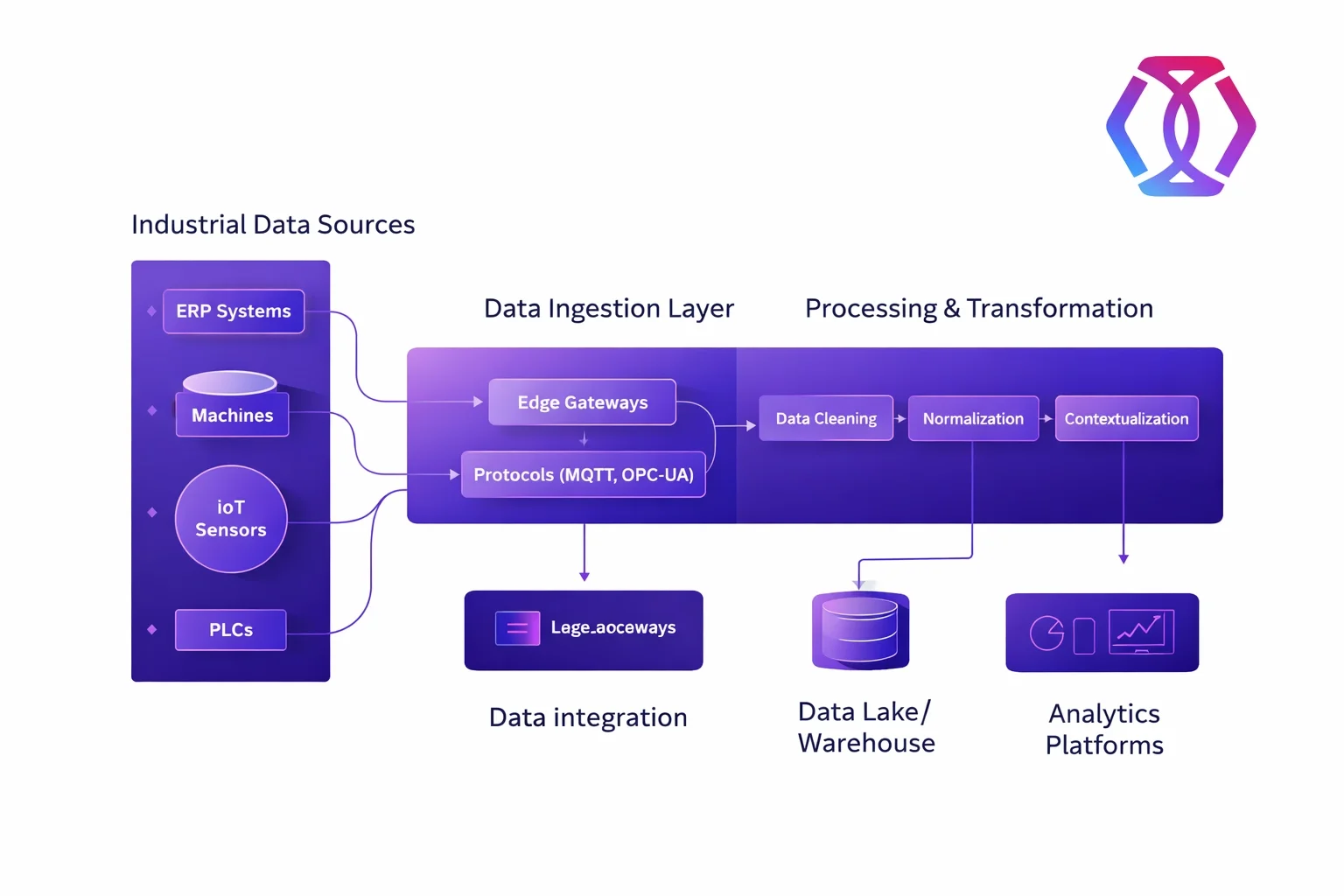
An industrial data pipeline is a structured flow of data from multiple industrial sources, like machinery with IoT sensors and ERP systems, through transformation into analytics platforms or data warehouses to ensure that industrial data becomes clean, consistent, and usable for dashboards, LLMs, and operational decisions.
Furthermore, different types of data pipelines address various operational and analytical needs, depending on how quickly data must be processed and how it is used. For example, automated pipelines include the following types:
- Batch processing pipelines are made for large volumes of data. They group it into batches and process it on demand. These pipelines are ideal for tasks such as historical analysis, reporting, or computationally intensive transformations, where real-time insights are not crucial.
- Real-time processing pipelines are a counterexample. They allow immediate reactions, which is perfect for predictive maintenance, anomaly detection, fraud prevention, etc.
- Data streaming pipelines offer continuous processing. Unlike real-time pipelines, streaming architectures maintain a constant flow of data for ongoing analysis when the conditions frequently change.
- Data integration pipelines consolidate data from multiple sources into a unified, consistent format. Moreover, they transform and enrich data as needed before putting it in data warehouses or data lakes.
Together, these pipeline types, if optimized, are irreplaceable for data pipeline automation because they allow manufacturers to transform fragmented data into actionable intelligence.
How to Move to Data-Driven Manufacturing Intelligence
Having optimized industrial data pipelines is one thing, but leveraging them for manufacturing intelligence is another. This section delves into the practical peculiarities of the transition.
The exact force application point in here is to change the raw machine data (at this point, it’s not the information) you get from the following:
- SCADA systems that monitor production machinery and equipment
- MES (Manufacturing Execution Systems) that track the operational layer: work orders and production status
- IoT sensors on the shop floor that measure temperature, pressure, vibration, other physical parameters, and so on
- ERP systems with inventory, orders, and planning data
Then, optimize the data flows in several directions:
- Change units (for instance, from imperial to metric or from voltage to temperature)
- Normalize the time series to vary sample rates as needed
- Identify interior problems with equipment that in the near future might lead to failures
- Control quality measures with statistical process control
As for the ways, these changes are usually incremental and aligned in the direction from the source to the target system. This way, the first step is always connected with the source. You need to reduce the amount of data and add the Extract-Transform-Load (ETL) pipeline design. According to it, raw data is gathered from multiple sources, transformed into a usable format, and then loaded into a target system such as a data warehouse or data lake.
Moreover, for high-volume production environments, it’s not as effective as designed. Due to the higher load, the Extract-Load-Transform (ELT) pipeline is more applicable here, instead of ETL. The difference is that this method first sends raw data to the target database, enabling the use of the database’s processing power additionally. Let’s consider closely.
Catch in Data Pipelines in Modern Manufacturing
In practice, data pipelines for manufacturing intelligence are something different than on paper. For instance, in the process, data anomalies may show up in many ways: sensor readings that are too high or low, or wrong inventory counts. That’s why data profiling methods may help find these problems before they influence other operations, including:
- Finding values that are statistically outside of typical operating ranges
- Recognizing patterns to find where machine performance data doesn’t match
- Checking the timestamps to ensure the production data is in order.
Time-series anomaly detection is very critical for further AI implementation because equipment measurements should follow some predicted patterns. Otherwise, the efficiency of the entire innovation is in question. Past performance data sets the right criteria and helps to flag unusual changes in time.
Signal Processing and ML Pipeline Integration
Machine learning relies on well-prepared signals. It means that in manufacturing, ML deals with noisy and high-volume data through preprocessing, feature engineering, and adaptive learning.
How does it work? First, ML processes the mixed signals to clean the input. It filters and normalizes raw sensor data to convert it into consistent learning signals that the model can interpret.
Then comes feature extraction. Here, data becomes patterns: frequency patterns, anomalies, trends, or statistical indicators. In our practice, we had a situation where a vibration signal was transformed into frequency-domain features using FFT. That helped detect mechanical failure early.
Once structured data is ready, the next step is for ML models to learn patterns of “normal” behavior. It’s done in this way: when incoming data deviates from the expected, the model flags it. When environments require real-time operation, ML models work as automated pipelines. So the actions are triggered automatically. Moreover, with time, models accumulate more patterns and improve continuously.
To sum up, ML deals with industrial data through the following cycle:
- turning raw signals into patterns
- learning to differentiate normal vs abnormal patterns
- continuously analyzing incoming data streams
- triggering actions in real time based on decisions
It brings us to the conclusion that without clean pipelines and signal processing, ML fails. So for a manufacturer, it’s crucial to combine the systems and sources into one continuous flow.
Bridging Machine Signals, AI Models, and Systems Together
It’s time for a word on integration, since this is a vital step. Let’s separate the notions.
Linking with Manufacturing SaaS Apps
If manufacturers use customized SaaS apps to do distinct tasks, pre-built data connections ease integration with ready-made connections for authentication, data mapping, and more. So when integrating SaaS and automated pipelines, some important things to think about are:
- Availability of APIs: Ensure that SaaS platforms have strong APIs.
- How often is data updated? Real-time processing or batch processing.
- Needs for data transformation: Formatting, amount, etc.
This prevents scope creep and ensures that the integration really helps stakeholders.
Best Ways to Integrate an ERP System
ERP systems store everything about finances, production, and inventories. When integrated properly, ERP systems link departments and locations to get a whole picture. Here are some best practices for integrating ERP with automated pipelines:
- Map data flows: Especially what data goes from one system to another.
- Set up rules for checking data: Make sure the data is OK at the input points.
- Synchronize in both directions: Updates should be possible from either system.
ERP integration often requires custom field mapping and transformation logic. In that case, ensure that product codes, customer IDs, and other identifiers are the same across all platforms for smooth integration.
Connecting to Databases
Manufacturing depends on massive databases: production data, quality control, and maintenance records. We’ve prepared some proven ways to connect to a database to automated pipelines, for instance:
- Direct links to databases for internal systems
- Change Data Capture (CDC) to find and work with just new or changed records
- ETL methods that can handle complicated changes
The main idea is that when creating database connections, think about where the data will end up. For instance, many manufacturers prefer a cloud data warehouse for consolidated information from various databases. However, others will serve their own servers for security reasons. But regardless of the storage place, gradual loading and segmentation algorithms will help you handle this whole amount of data more effectively.
If you’re interested in embedding AI in legacy systems, read our recent article introducing 9 steps to approach from SCADA to smart factory.
Ready-to-Implement Guide
As a brief conclusion, let’s synthesize the stages from raw machine signals into production intelligence:
- Capture Signals: You need to install IoT sensors on machinery and equipment or integrate existing outputs.
- Build Data Pipelines: Leverage the data streams according to the necessary framework: the Extract-Transform-Load (ETL) or the Extract-Load-Transform (ELT) pipelines.
- Apply Signal Processing: Remove noise, detect anomalies, and extract patterns from data.
- Train ML Models: Use structured data for predictive maintenance
- Close the Loop: Feed predictions back into operations and leverage the results.
That’s it. Your manufacturing process is more resilient and future-proof than it was before. However, let’s discuss possible pitfalls you might encounter in the process and how to minimize them.
The Sticking Points of Manufacturing Intelligence
If a smart factory, including industrial data pipelines, is so good, why don’t manufacturers implement it here and there? As a matter of fact, although over 70% of manufacturers (Chinese market) are focusing on digital transformation, only a few reach true manufacturing intelligence. Here’re the most common challenges we’ve seen in the process:
- Legacy Tech: Many factories run decades-old equipment (even 30 years old) with proprietary formats or tangled processes.
- Too Much Data: Machines generate terabytes of sensor data daily; that’s too much for real clients’ opportunities.
- Real-Time Needs: Delays in processing disrupt production.
- Poor Data Quality: Data silos, noise, missing values, and inconsistent formatting are common issues preventing successful data utilization.
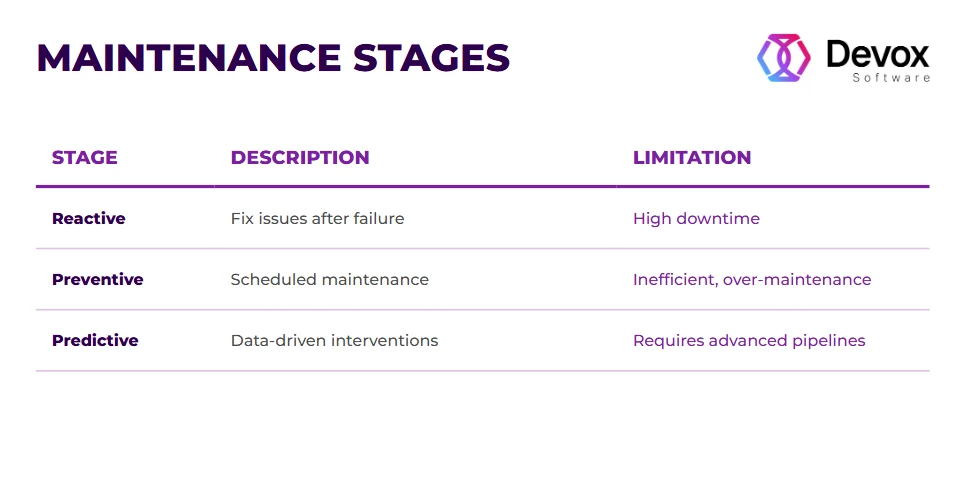
What to do? To overcome these challenges, manufacturers need to focus less on replacing systems and more on data flows; for instance, introduce a scalable data pipeline layer that integrates legacy equipment, standardizes and cleans incoming data through signal processing, and streams it in real time to centralized platforms.
Moreover, data quality delivers reliable value for analytics, while event-driven architectures enable near-immediate response. Most importantly, the true success comes from incremental integration rather than full replacement, which is often misinterpreted as legacy modernization.
Wrapping up
These days, industrial leaders invest in AI. The best step to start AI introduction is to prepare your tech for the change, as soon as automated pipelines built today are the foundation for tomorrow’s autonomous factories. This mental shift is already happening, from collecting data to processing it.
Being AI-native is not a marketing fuss. Through projects, Devox Software has witnessed the tangible business value brought by technological and structural shifts:
- Companies with automated pipelines achieve faster decision cycles.
- Proper signal processing improves model accuracy.
- Integration, not algorithms, is the #1 bottleneck in most cases of modernization.
Frequently Asked Questions
-
What is the primary goal of industrial data pipeline automation?
The goal is to eliminate manual data processing: from automating data input to data handling, storing, and reducing latency in the process. When done correctly, data pipeline automation guarantees the timely delivery of machine data to analytical engines, enabling immediate operational actions and yielding real business results.
-
How does signal processing for machine learning improve production?
With signal processing for machine learning, environmental noise is filtered out to isolate true learning signals. This way, models identify early signs of equipment fatigue, improving predictive maintenance at large.
-
Why should I choose Devox Software for manufacturing intelligence solutions?
Devox Software is a pro at the complex integration of hardware signals with software intelligence. As soon as we’ve dealt with rows of manufacturing intelligence solutions, we know all the pitfalls on the path to ensuring your data infrastructure is driving actual ROI. And we will save your time and effort thanks to this.
-
Can existing machines be integrated into automated pipelines without replacement?
Yes. Most legacy equipment can be retrofitted with IoT sensors to capture raw data. The real hurdles here are equipment licensing restrictions and technical requirements. As a result of improvement, these automated pipelines give older machinery modern “intelligence” capabilities at a fraction of the cost of new equipment.


