









Modern event-driven architectures and integration layers can make rigid batch-based production systems viable and competitive in 2026 and beyond. Yet, no core infrastructure replacement is needed. Does that sound appealing?
If yes, this article explains exactly how event-driven data architecture modernizes legacy manufacturing environments. It’s based on our field notes from our experience for CTOs and CIOs about how smart factories leverage open database architecture and event-driven systems without major reworks and investment. But before we move to the particular know-hows, let’s build a foundation for the shift.
What Is Batch Manufacturing Today? Challenges and Bottlenecks
Batch manufacturing issues products in grouped production runs rather than through continuous real-time processing. Traditionally, manufacturing systems complete one batch before moving to the next, with operational data, quality reports, and production analytics often processed afterward in scheduled intervals. It perfectly worked and delivered predictable workflows, stable scheduling, simplified inventory management, and controlled production cycles. But not these days.
These days, it’s not enough. Volatile supply chains, demand for customization, shorter delivery cycles, and rising operational costs make traditional models inefficient and increasingly become operational bottlenecks. Out of these, the modern challenges arise as follows.
| Operational Impact | |
| Delayed production visibility | Slower response to disruptions |
| Reactive maintenance | Increased downtime risks |
| Data silos | Inconsistent decision-making |
| Limited scalability | Difficulty integrating AI and IoT |
| Rigid workflows | Reduced production flexibility |
| Delayed quality detection | Increased scrap and rework |
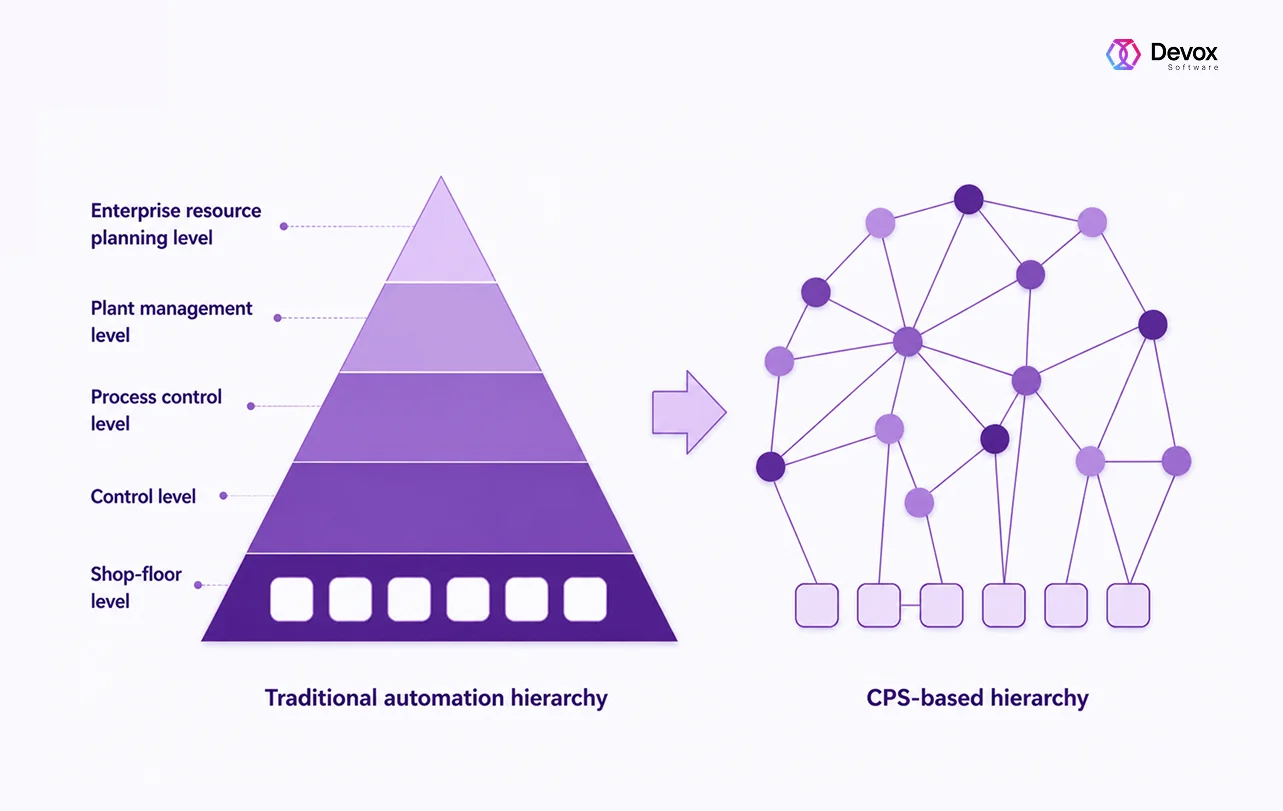
One solution is to build a decentralized, connected factory structure (CPS-based automation hierarchy), while event-driven architecture enables real-time data flow and reactions between those systems. However, it may require additional rewrites with all connected risks.
That’s why in pursuit of battling these restrictions, modern smart factories increasingly move away from static batch-driven architectures toward event-driven and continuous processing environments. Instead of waiting for completed production runs, scheduled reports, and end-of-line inspections, modern manufacturing systems process operational events continuously in real time.
Through software modernization and event-driven data architecture, companies extend existing MES and production systems with:
- real-time data pipelines
- industrial middleware
- cloud connectivity
- AI-driven analytics
- open database architecture
This creates hybrid manufacturing ecosystems where traditional production processes coexist with real-time operational intelligence.
From Batch to Continuous Processing
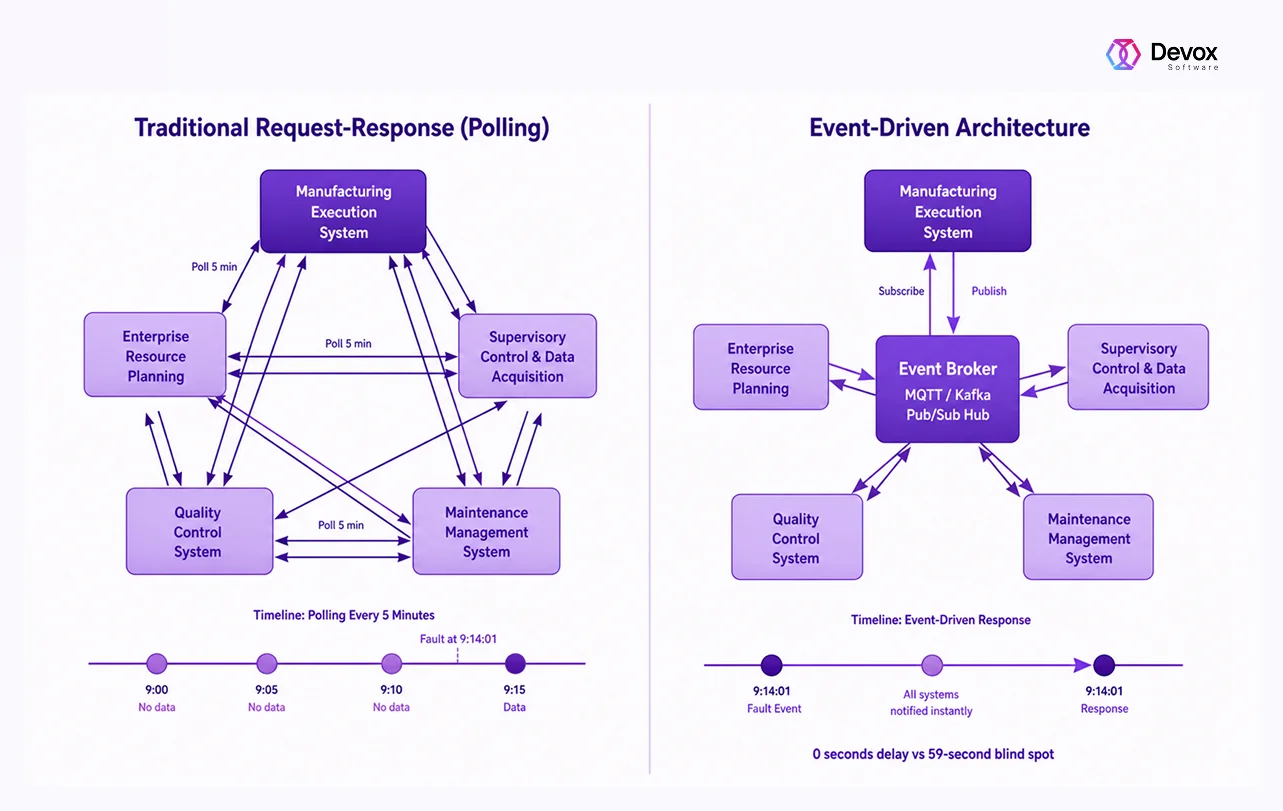
Event-Driven Architecture (EDA) flips traditional models entirely. Instead of scheduled requests, event-based systems listen for events and react the moment a certain volatility or deviation occurs, issuing an immediate response.
What can be such an event? Almost everything. In manufacturing, an “event” becomes any significant occurrence: the end of the cycle, an anomaly detected by a sensor, a failed inspection, and more. And the best part is that, immediately after the event is tracked, all interested systems respond in parallel with coordinated actions. This feat is made possible by three components:
- event producers (PLCs, sensors, machines) that generate events
- event consumers (MES, ERP, maintenance systems) that react to them
- event broker that routes events and keeps a durable log
The broker decouples systems, so they don’t depend on each other. This way, adding new integrations becomes simple. Just subscribe to events without changing existing systems.
Moreover, unlike polling, event-driven systems also preserve data integrity. If a system goes offline, it can replay events from the log once it’s back online, ensuring no data is lost.
For instance, when a machine finishes production, the event occurs with corresponding actions: updated stock levels, logged maintenance logs, scheduled quality assurance, etc. It acts like a continuous ecosystem. As a result, you get faster anomaly detection, dynamic optimization, and resilience.
Core Pillars of Event-Driven Data Architecture
As a CPS-based automation hierarchy replaces traditional multi-layer system pyramids with a flexible network of intelligent agents, it needs a consistent rework for implementation.
Event-driven data architecture, on the other hand, enables real-time data flow and reactions between those systems. Here, we come to the question of how to build an event-driven architecture without any rewrites.
Where to start? The hardware is already in place. Sensors, PLCs, and SCADA systems are running and generating data every second. The core stack we’re dealing with is:
- an event broker (Kafka, MQTT)
- a translation layer to connect legacy systems (Node-RED, middleware, APIs)
But the real work is not technical; it’s defining what actually matters and how to connect it for real business value.
Pillar 1. Define Events, Not Data
A single sensor can generate thousands of readings per day. So you need to sift the meaningful ones and transmit them further in the systems:
- which deviations trigger failures
- which delays cascade into downtime
- which variations are acceptable
Example. What is an event, and what is not in the event-based systems
| Not an event❌ | Event✅ |
| temperature = 72°C | The temperature exceeded the threshold.
The temperature remained abnormal for 3 minutes. The temperature trend indicates failure risk. |
| cycle count = 1543 | The machine stopped unexpectedly.
The cycle time increased by 20%. The machine is idle for longer than expected. |
| order #123 in progress
50 units completed |
The production delay exceeds the planned schedule.
The order risks missing the deadline. A bottleneck was detected on the production line. |
This way, events represent exceptions, state changes, or risks. It’s not raw numbers that only lead to alert fatigue.
Pillar 2. Find the Ultimate Value Point
In most cases, this point is where delay costs money. This is how to find your weak link. That delay shows up as a latency problem:
- unplanned downtime that is reported minutes too late
- quality issues discovered only after the batch is complete
- bottlenecks that go unnoticed until they impact the entire line
- inventory shortages are identified after production is already affected
That’s why you don’t need to modernize everything at once. Trying to rebuild the entire system increases risk, slows progress, and delays ROI. Instead, identify where latency hurts the most and start there for event-based systems.
Helping Questions
Which delay stops production?
Which delay creates scrap or rework?
Which delay cascades into other systems?
Example. How it works
Even if sensors are in place, downtime is often reported late, simply because the system reacts too slowly. So, instead of logging downtime after a cycle and notifying teams minutes later, you automatically trigger an instant stop event routed simultaneously to maintenance, production scheduling, and analytics. So, one event triggers a chain of immediate actions.
As a result, an event-driven system operates in milliseconds instead of minutes. This shift alone reduces manual intervention and improves process completion rates significantly.
Pillar 3. Build Around the Broker
The event broker is the simplest part of the architecture. It receives events, routes them to subscribers, and stores them in a durable log. That’s all it does, and tools like Kafka or MQTT already solve this reliably. Here comes the hard part, the integrations. The real challenge is how to make existing systems produce, understand, and act on events.
Helping Questions
- Event Producers. Which machines or systems generate the most critical signals?
- Event Producers. What condition actually matters (threshold, anomaly, trend)?
- Event Producers. Are we sending raw data or meaningful events?
- Event Consumers. Which systems need to react immediately?
- Event Consumers. What action should be triggered automatically?
- Event Consumers. Can multiple systems act on the same event?
- Integration & Translation. How will legacy systems receive events (API, middleware, adapters)?
- Integration & Translation. Do systems need transformation or enrichment before consuming events?
- Integration & Translation. Where do protocol mismatches exist?
- Event Design. What defines a “critical event” vs. normal behavior?
- Event Design. What thresholds trigger action?
- Event Design. Do we need aggregation (e.g., repeated anomalies)?
- Reliability. What happens if a system is offline?
- Reliability. Can events be replayed?
- Reliability. How do we ensure no critical signal is lost?
Practical Example. Quality Deviation on Production Line Scenario
Here is an example of how to manage quality-based events on a production line event-based systems.
| Before Event-Driven Architecture | After Event-Driven Architecture | Business Impact | |
| Detection | The vision system detects an anomaly | The vision system detects an anomaly and generates an event | Same detection, different reaction speed |
| Data Handling | Data stored locally | Event published instantly via the broker | Eliminates data silos and delays |
| Processing | Quality report generated after batch | Real-time event routing through a broker | Immediate processing instead of delayed reporting |
| System Response | The issue escalated manually | MES flags issue, quality system logs the defect, and the dashboard alerts the team | Automated, simultaneous reactions |
| Production Adjustment | No immediate action | Production slows or adjusts automatically | Prevents defect propagation |
| Speed of Reaction | Minutes-to-hours delay | Real-time (milliseconds to seconds) | Faster decision-making |
| Outcome | Defects accumulate, scrap increases | Immediate intervention, minimal defects | Reduced waste and higher efficiency |
| Overall Model | Reactive, batch-driven | Real-time, event-driven | Shift to proactive operations |
Pillar 4. Bridge Legacy Systems
As a matter of fact, legacy systems were not designed for events. In particular, MES expects structured workflows. ERP relies on scheduled queries, while quality assurance systems often process batch data after production cycles are complete. They are not attuned to operational changes in real time as they poll, wait, and synchronize later. That’s why this kind of translation becomes critical.
So, what does this connection layer look like? It connects legacy systems to the event stream with real-time factory events, which are converted in a way that legacy systems can understand. It can look like this.
| Translation Layer Role | Practical event-based systems result | |
| MES expects workflow updates | Converts events into MES-compatible API calls | Work orders update automatically |
| ERP relies on scheduled queries | Pushes production or inventory events into ERP | Inventory reflects changes faster |
| Quality system processes batch data | Sends defect events in real time | Issues are logged before batch completion |
| Machines use industrial protocols | Translates OPC UA, MQTT, or proprietary signals | Factory data becomes usable by modern systems |
| Data formats are inconsistent | Reshapes and normalizes event payloads | Analytics systems receive clean data |
Helping Questions
Which legacy systems still depend on scheduled exports or manual checks?
Which systems need real-time updates but currently receive data too late?
What formats or protocols prevent systems from communicating?
Which events should trigger an API call, workflow update, or alert?
Where do operators still copy data between systems manually?
Practical Example: Abnormal vibration.
Without a bridge, the signal may stay inside the machine or SCADA layer until someone checks a report.
With a translation layer, the sensor sends a vibration signal, then:
- Then middleware converts it into a structured event named, for instance, “abnormal_vibration_detected.”
- The broker then publishes it
- The maintenance system creates an inspection task
- MES marks the machine as at risk or accordingly
- Analytics logs the event for failure pattern analysis and flags the event
This way, one signal becomes a coordinated action chain across multiple systems.
Pillar 5. Build Without Disruption
So while your legacy systems continue running, you add event-driven workflows alongside them. Over time, polling reduces, and data consistency improves continuously without the full rewrite. Instead, you introduce event-driven logic on top of your systems. It is better to do this in the following sequence:
- Add events for one use case
- Expand event usage
- Reduce polling
iterating over time. This way, legacy systems stay stable while behavior becomes modern.
Helping Questions
- Which processes cannot tolerate downtime?
- What must continue running unchanged?
- Where can we safely introduce parallel workflows?
- Which delay has the highest cost?
- Where can we introduce one event with immediate ROI?
- What process can run both old and new logic in parallel?
- Can we add events without modifying the core MES?
- Where do we overlay instead of replace?
- Which systems can consume events without a full redesign?
- What happens after the first success?
- Which next bottleneck should we target?
- How do we measure improvement at each step?
Practical Example Production Delay Handling Scenario
This table shows the impact of the event-driven layer before and after the implementation, as per each stage.
| Traditional polling systems | Event-based systems | Value | |
| Delay Occurrence | A delay happens on Line A | A delay occurs and triggers the event instantly | Immediate awareness instead of a hidden issue |
| Detection | Reported in the next MES cycle | Event published in real time | Eliminates detection lag |
| Scheduling Response | The scheduler reacts later | The scheduling system adjusts the plan instantly | Prevents cascading delays |
| Operational Visibility | No immediate alerts | Dashboard alerts the operations team in real time | Faster decision-making |
| Downstream Impact | Downstream processes already impacted | Downstream lines adapt automatically | Minimizes disruption propagation |
| Overall Effect | Delay propagates through the system | Same systems, real-time response | Shift from reactive to proactive operations |
Pillar 6. Scale Through Proven Impact
One of the common mistakes is to treat event-driven data architecture as an infrastructure upgrade. Don’t focus on brokers, topics, and flow charts; consider the business value in the first place. A simple loop can help:
- Identify the highest-cost delay
- Fix it with real-time events
- Measure the impact
- Expand to the next bottleneck
Helping Questions
Where do we lose the most money per minute?
Which delay affects multiple systems?
What issue is always discovered too late?
What KPI will improve (downtime, scrap, OEE)?
How fast should response time improve?
Can we measure before vs after clearly?
What is the next bottleneck after this one?
Can the same event-driven pattern be reused?
Which system benefits most from real-time data next?
Practical Example of the Implementation Roadmap
This is how we can treat the scaling phase as it goes to multiple locations, production lines, and factories.
| Step | Action | What Happens | Result |
| Step 1. Identify the Problem | Analyze where delays cost the most | The factory notices unplanned downtime, slow maintenance response, and production losses during shift changes | Downtime is detected late due to polling-based reporting |
| Step 2. Introduce Event-Drive-n-Fix | Add a real-time event for machine stops | Machine stop triggers an instant event routed to maintenance, MES, and the operations dashboard | All critical teams receive the signal immediately |
| Step 3. Measure Impact | Compare before vs after | Downtime detection drops from minutes to seconds, maintenance reacts faster, and uptime improves | Clear ROI is proven from one use case |
| Step 4. Expand | Apply the same pattern to the next bottlenecks | Quality deviations, production delays, and inventory shortages are converted into real-time events | Event-driven architecture scales through proven business impact |
As a result, despite obvious event-driven architecture pros and cons, each event is solved with the same pattern.
Furthermore, more modernization strategies are applicable to factories. It involves MES modernization, intelligent automation, and AI implementation on top of legacy systems. The next step is Industry 4.0.
Key Insight
Event-driven architecture is not about streaming more data or streaming more quickly. It’s about detecting relevant and value-driven data, transforming it into insights, and reacting to them at the right moment. That’s what turns connected batch-based into intelligent continuous production systems.
Enabling Smart Batch Production with Devox Software
With event-driven architecture, replacing systems is unnecessary. The only thing critical is eliminating delay. Today, manufacturers have data, but they lose velocity because they react too late. Batch-based systems, polling cycles, and fragmented integrations create gaps between what happens on the shop floor and how quickly the business responds.
Event-driven data architecture closes that gap. From critical changes to real-time events, factories move to intelligent systems:
- to instant awareness
- to automated responses
- to coordinated operations
Devox Software is an experienced legacy modernization partner. We modify legacy systems step by step, identifying high-cost delays, solving them with real-time events, and expanding based on measurable business impact. With our pre-made pipelines, AI Solution Accelerator™, and vetted teams, we deliver significant impact for real-time, intelligent production environments.
Frequently Asked Questions
-
What are the main legacy system modernization approaches for factories?
The main set of common choices includes the “Strangler Fig” pattern (gradual module replacement) and API-fication of legacy systems. The choice of legacy system modernization approaches depends on how critical downtime is and the level of flexibility of your current MES/ERP architecture.
-
How does event-driven data architecture improve factory OEE?
Event-driven data architecture allows for an instantaneous response to incidents of whatever nature they are, rather than waiting for the current “batch” to complete. This reduces downtime and directly increases Overall Equipment Effectiveness (OEE).
-
What is the benefit of moving from batch to continuous processing?
The primary benefit of batch-to-continuous processing is total transparency. You can see the real-time status of production every second, which prevents error accumulation and allows for optimized internal shop-floor logistics. Moreover, if something goes wrong, the system reacts immediately, saving time and mitigating possible downtime.
-
Why is small batch production easier with event-based systems?
Unlike rigid batch systems, event-based systems allow for the dynamic reconfiguration of part-processing routes. This provides the ideal foundation for small-batch production, where each unit has unique parameters and requirements.
-
Is software modernization risky for an active production line?
When using the correct software modernization strategies, such as parallel runs or phased data migration, risks to active production are minimized, ensuring a smooth transition to modern Industry 4.0 standards.

![Devox Software is Ranked Among Best-Performing B2B Companies [Clutch Report 2022]](https://devoxsoftware.com/wp-content/webp-express/webp-images/doc-root/wp-content/uploads/2023/05/getty-images-9IENlqTm5ds-unsplash-1024x652.jpg.webp)
