
















Table of content
Is your automation still clicking buttons — or rewriting its logic?
Most enterprises stall at task automation. Bots mimic keystrokes and shave minutes off routines, but AI business automation shifts the focus from faster clicking to smarter thinking.
But not all business process automation advances the business. The real value comes when automation not only accelerates tasks but transforms the way work happens. When BPA redefines what a step actually means, and the old rulebook of operations — predictable, siloed, linear — gets replaced with a living, learning network.
This article lays out how to build automation that thinks, adapts, and delivers. Launch with clarity, measure what matters, and prove ROI in results.
Core advantages of AI-driven process optimization
What Is AI Business Process Automation? Most companies start with bots that mimic clicks. A few evolve into systems that adapt in real time, without human input. Between those two points lies a curve that defines how AI transforms operations: where are you on the curve? what’s blocking the next jump?
Let’s map it out.
The graphic below shows how AI-powered automation evolves — from simple task bots to fully autonomous enterprises. Where do you think your company fits on this curve?
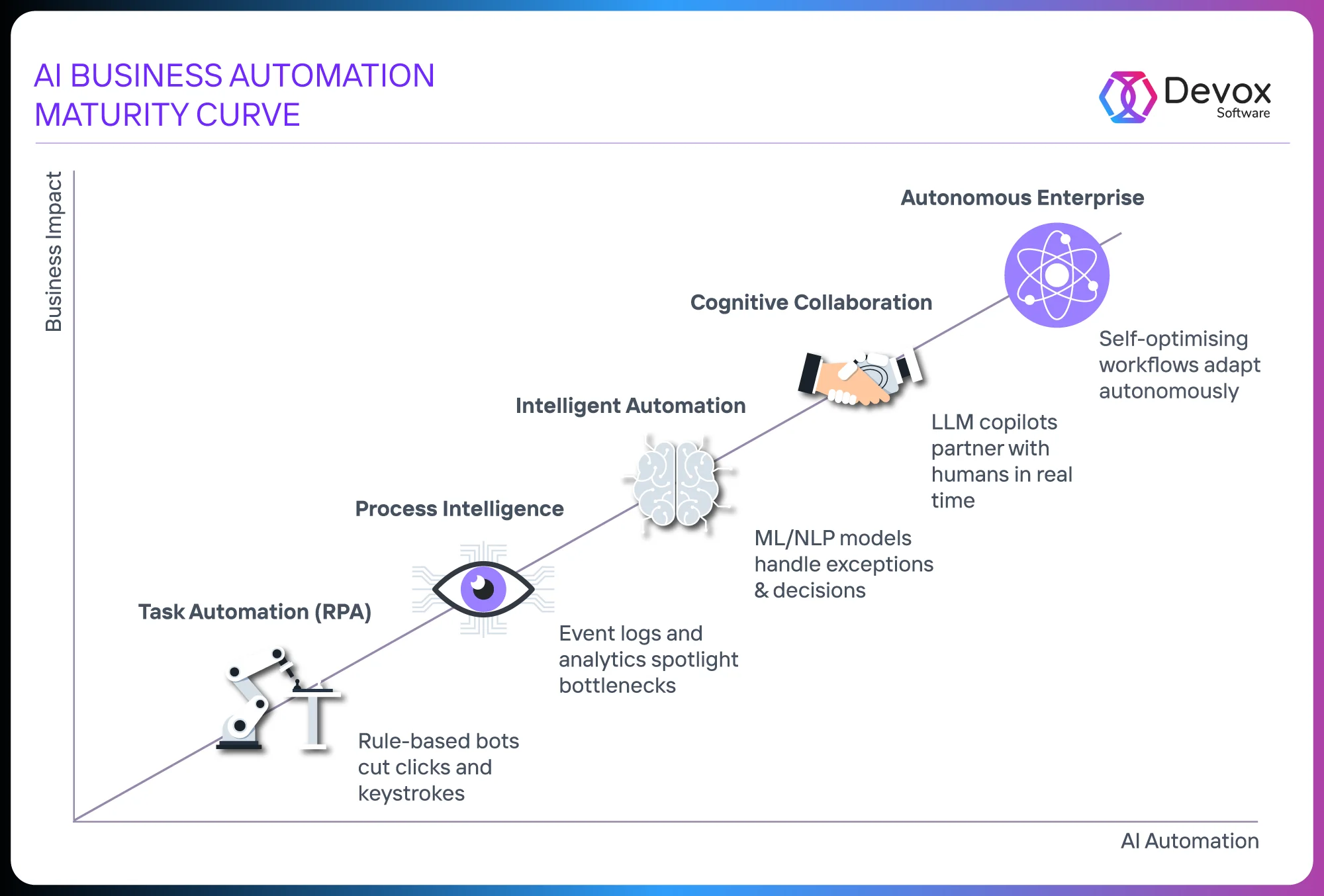
Think of it this way: traditional automation follows a script. AI writes its own. At a high level, utilizing AI for business automation involves integrating machine learning, NLP, and generative models directly into workflows. The result? Processes that:
- Sense what’s happening in real time (from system logs, sensors, or user actions)
- Decide the best action based on predictions or pattern recognition
- Act by triggering tasks, generating documents, or allocating resources — instantly
- Learn from the outcome, adjust, and improve with every cycle
Interestingly, business process automation with AI isn’t new. What’s changed is what AI makes possible: decisions in motion. Here are the real gains.
Cycle-Time Compression
Prediction engines now reside within the workflow, not alongside it. When an event fires, AI models respond before the next step begins. For example, at Mars Wrigley Company, line-fill forecasts moved from daily batches to real-time triggers. That shift reduced fulfillment delays and improved on-time delivery scores, without increasing headcount.
First-Pass Yield Uplift
Upstream classification catches errors before they reach the systems of record. PepsiCo used invoice classification to cut rejection rates on the first submission from 30% to 4%. Rework dropped, and cash flow became more predictable. Accounts payable turned from a blocker into a control point.
Working Capital Release
Inventory and receivables no longer sit idle. For instance, british telecom operator re-engineered its service activation process by using AI to automate business process steps that matched production with verified demand. Lead time dropped from 90 to 30 days. That meant recovering two months of working capital, with no additional labor and no legacy process burden.
Cross-Silo Visibility
AI connects fragmented systems into a unified view of operations. Siemens and Reckitt used process mining to align CRM, ERP, and WMS data. Once every team saw the same sequence of events, manual reconciliations stopped.
Self-Tuning Governance
Every decision generates data. When drift exceeds tolerance, retraining triggers automatically. No waiting for audits. McKinsey’s 2025 benchmark shows the strongest EBIT gains in firms that embedded model refresh into AI governance as a system feature.
Now the real challenge begins.
Start Where it Hurts: Picking the Right Process for AI
AI succeeds only where the process bleeds in plain view. Look for the flow that forces managers to open a spreadsheet at 7 a.m., the one that triggers three “just checking” emails before lunch, the one finance downgrades to “manual adjustment” at month-end. That is your launchpad.
A great example of how does AI automate business processes, described in HBR, is Mars Wrigley’s packing line pilot, where live sensor data is fed into predictive models, instantly adjusting fill rates to cut waste and improve margins. A digital twin fed live weights into a small prediction model; waste fell by double digits in the first quarter, and no one asked why the pilot mattered. PepsiCo chose accounts payable, not for technology glamour, but because every rejected invoice froze cash. After mapping the hand-offs, they trained a classifier to flag mismatched fields; rejection rates dropped from thirty to four percent, cycle time halved, and working capital loosened immediately. Both stories share a single constant: the target process has already measured its pain in money and minutes.
Find the delay that makes the CFO say, “This is just how we’ve always done it.” Follow the duplicate entry that turns a clean order into a credit note spiral. When a process owns a metric that causes pain, AI has leverage. Without that leverage, every model stays a prototype. Find the hurt, prove the dollar, and then automate.
A quick CFO-grade scan: log the actual time of every step in the flow for one ordinary week; multiply idle minutes by cost of capital; tag each hand-off by variance and rework count; rank the sequence by total drag. The step with the highest weighted score reveals the process that funds its automation. When the metric clearly reflects a business problem, AI gains real leverage.
Executives rely on clean diagrams; engineers deal with messy logs — timestamps, errors, user IDs. Start with the raw event log: order IDs, status changes, server times. The actual process rarely matches the Visio, and understanding this gap is key to answering how does AI automate business processes based on what actually happens, not what’s documented. That gap is everything. It’s how AI automates what actually happens, not what’s supposed to. You’ll see loops where diagrams show straight lines, rework cycles, and “manual review” stretching across weekends. The real flow — not the documented one — decides whether automation works.
Three signals confirm that a process can sustain AI.
1. Stable pathways
Eighty percent of cases should follow fewer than five unique variants. When variants explode into the hundreds, the process behaves as loosely coupled workarounds, and a model trained on last quarter’s data will chase noise.
2. Trusted data spine
Core entities — customer, SKU, invoice, shipment — must share keys across systems. If each department renames the same object, feature engineering turns into archaeology.
3. Owned exceptions
Each exception must have one accountable owner. For example, sensor faults route to maintenance; supply constraints route to planning. Undefined ownership keeps exceptions in email limbo, stopping any feedback loop that would retrain a model.
Run one week of logs and you’ll see exactly where AI uses software to automate business processes most effectively, especially when variant count, foreign key consistency, and exception ownership align. If the numbers align with the three signals, the process will absorb predictive models and automation bots without unravelling. If they diverge, fix the structure first; algorithms thrive on discipline, not aspiration.
Process mining reveals the real bottlenecks
This is where the plot thickens. The output of process mining can look chaotic, like a tangled spaghetti diagram colored by throughput time. Thicker lines show higher frequency, darker shades indicate longer delays, and the knots mark true work stoppages. In one finance function, a supposedly “straight-through” invoice flow displayed 312 unique paths; three of them handled 82 percent of volume, the rest existed to reprocess mistakes. The longest knot sat between “posted” and “approved,” adding an average of forty-six hours because two legacy fields required manual cross-checking. No workshop had surfaced that fact; it showed up within fifteen minutes of reviewing the event log.
The insight is immediate. Bottlenecks are not abstract lean wastes or opinions in a meeting. They are precise coordinates in time and a system where cases pile up. Remove that knot by rule, by RPA bot, or by retraining staff, and AI process optimization enables cycle time to collapse without touching the rest of the flow. An AI model introduced afterward inherits a cleaner signal, learns faster, and stays robust because variance has been stripped at the source. That is the sequence: mine, expose, simplify, then model.
The Readiness Signals Leaders Often Miss
Leaders usually gauge readiness through project charters and workshop outcomes, yet the decisive indicators hide inside daily execution traces.
A process signals maturity when its variants concentrate rather than scatter. Twenty paths covering eighty-plus percent of cases suggest predictable behaviour that an algorithm can generalise upon. Data lineage also speaks: identical primary keys move intact from CRM to ERP to warehouse logs, which means feature engineering requires configuration, not forensic recovery. Time stamps follow a uniform standard; millisecond precision at each hop turns cycle-time analytics into science rather than estimation. Exceptions carry explicit taxonomy and ownership — “credit hold,” “price mismatch,” “partial fulfillment” — so every deviation already drops into a bucket with a person’s name on it, giving supervised models a clear label set. Finally, change history sits in version control instead of email threads; each tweak to validation logic or routing rules appears as a commit with author and rationale, making drift analysis straightforward.
When these patterns surface in the logs, the process stands ready for predictive models, RPA orchestration, or LLM validation. The groundwork exists; automation layers add velocity rather than volatility.
Now we hit the real challenge. Metrics before models — or it’s just guessing:
- Step 1. Cycle-time, first-pass yield, rework hours, cash trapped in queue — pick three that map cleanly to revenue or cost.
- Step 2. Instrument each step to emit a timestamp and a status code. Use one operational week to fix the baseline: median, 90th percentile, and extreme outliers.
- Step 3. Mark the cutoff that defines success (e.g., invoice approved in under two hours, return processed with zero manual touch).
Think of this baseline as your reality check. Before trusting any AI, ask: did it help us move faster, reduce costs, or unlock stuck money? A smart model that improves accuracy but leaves delays untouched is just smarter — not better. Only when metrics show actual financial movement — faster cycle time, fewer manual fixes, smaller inventory — can you call it a win. Without that, it’s just a nice demo.
People, Data, and Systems: the Real Enablers
Four systems, zero shared truth.
Invoice data starts life in the CRM as a quoted price. By the time the same order reaches the ERP, its currency has changed, the warehouse log shows a split shipment, and Finance closes the month with a manual credit note because the tax code in the original line item never mapped to the general ledger. Nothing here is a modelling problem; the fracture sits in the information spine.
McKinsey’s 2025 survey captures the cost of that fracture. Risk and data governance are the two most centralised elements in companies that show EBIT impact from AI, while tech-talent deployment remains hybrid. Centralisation matters because a single identifier must travel the entire workflow unedited. When the identifier drifts — even by a trailing space — every downstream model learns a different universe. Half of the enterprises reporting negligible AI value still load data through batch jobs that rewrite keys; they spend more on reconciliation than on inference.
The remedy is architectural, not algorithmic. A shared event backbone carries immutable order IDs; each system emits state changes as append-only events. Master-data governance assures that “customer,” “SKU,” and “contract” remain canonical entities, not department dialects. Version history travels with the event, so lineage questions resolve in milliseconds.
Once the spine holds, AI absorbs coherent signals. Forecast variance decreases significantly because AI for process optimization reads sales and operations from one calendar, aligning predictions to reality. Anomaly detection stops flagging every third transaction as suspicious because the shipping address in the order now matches the address in the invoice. Transformations that once required weekend cut-overs become rolling deployments — new attributes slide into the schema without breaking downstream joins.
Every hour invested in standardizing data pays off in model stability. Until the systems share truth, AI exposes organizational inefficiencies. When the pipeline receives a consistent view of the data, the models produce insights you can use.
Who owns the process, not the department
The value chain respects no org chart. Cash moves from quote to wallet through sales, operations, logistics, and treasury. When each director guards only the slice under her P-L, cycle-time stretches to the slowest hand-off. Harvard’s January 2025 study names ownership the first requirement: one person holds full accountability, budget authority, and the power to change rules. European manufacturers learned this early — Siemens assigns an Order-to-Cash owner with veto power over both sales scheduling and plant sequencing; the role lives outside either function.
McKinsey’s 2025 survey reinforces the point: enterprises with CEO-level governance over AI workflows report the highest EBIT lift, because a single chain of command resolves model drift, data standards, and exception policy in one decision, not four meetings. The process owner becomes the stabiliser for automation; models retrain on consistent logic, RPA scripts survive org shuffles, and metrics align with the only perspective that matters — flow, not department.
These projects show the same pattern: map the messy reality, quantify the drag, then let targeted AI — process mining, ML prediction, and decision intelligence remove the drag at scale.
RPA, ML, or LLM: what’s right for you?
Aligning the mechanism with the signal and control
Deterministic surface: RPA
User interface elements sit in fixed coordinates, and decision logic stays explicit. A bot grabs the DOM node, inserts the value, and fires the event. Error occurs only when the surface shifts: version upgrade, layout tweak, or unexpected pop-up. Governance consists of UI monitoring and rapid patch cycles. CapEx low, payback immediate, scalability linear with bot licenses.
Stochastic metric: ML
Sensor voltages, lead-time deltas, and historical demand curves embed variance that conforms to distributional law. Gradient models produce a bounded forecast with confidence intervals. Model refresh cadence links to distribution drift: faster in seasonally volatile businesses, slower in regulated batch production. Infra cost rises with feature volume, yet ROI tracks directly to reduced buffer stock, tighter provisioning, and fewer warranty claims.
Semantic entropy: LLM
Free-form purchase notes, contract clauses, and warranty requests express business intent through language variation. Sequence models convert raw tokens into embeddings, extract intent, summarise action, and generate canonical objects. Effectiveness hinges on prompt discipline, safety filters, and domain fine-tuning. Value emerges when language ambiguity stalls throughput: manual triage collapses, exception queues shrink, and compliance text gains an instant first draft.
Decision grid for the architect:
| Signal profile | Control surface | Learning burden | Latency target | Mechanism |
| Fixed cursor fields, predictable branching | UI scripting | Zero | Sub-second | RPA |
| Historical variance, numeric target, labelled outcome | Feature store + model registry | Scheduled retrain, drift watch | Tens of ms to minutes | ML |
| Unstructured text, multi-topic, domain jargon | Prompt library + vector index | Continuous feedback, guardrails | Seconds | LLM |
The choice of engine shapes both ROI and risk profile. Misalignment often brings side effects:
- RPA used in judgment-heavy workflows.
- ML applied to shifting language data.
- LLMs deployed in static, low-variance fields.
In contrast, hybrid pipelines tend to deliver better balance:
- LLM extracts structured JSON from inbound email.
- ML estimates fraud probability.
- RPA transfers validated entries to ERP.
Each step can be monitored, versioned, and traced end-to-end.
Visible Pressure
If you’re asking how does AI and automation help smal businesses, start here: it doesn’t begin with vision decks. It starts when a recurring cost, delay, or bottleneck becomes too visible to ignore — and the AI gets the green light. Days sales outstanding are rising by three days past term. A 26% invoice rejection rate that locks payables into manual loops. Order fill is degrading under rework costs that don’t show up until the quarter closes. These aren’t back-office annoyances — they’re slow leaks into margin, liquidity, and customer patience.
At PepsiCo, the rejection rate on accounts payable hit 30% after an ERP cutover. No one planned for it. The cost wasn’t just labour — it was missed discounts, supplier frustration, and excess working capital. Only when the numbers showed up in write-offs did the classifier get funded. Within weeks, the rejection rate dropped to 4%. Not because someone had a roadmap. Because the P&L absorbed one pain point too many.
Executives in our segment — COO, CFO, heads of shared services — move when inefficiency becomes visible outside the function. When sales escalate, delays. occur when Treasury models break because the cash flow forecast drifts too far off. When a competitor halves delivery lead time and starts winning deals that should have been yours.
McKinsey’s 2025 data shows that 21% of companies redesign at least one end-to-end process within a quarter after a competitor deploys AI inside that same process. Because cycle time and customer responsiveness are now strategic. AI is not adopted because it is innovative. It is adopted when the cost of delay becomes measurable.
If the pain isn’t quantified — if it’s not expressed in euros lost, days delayed, or customers churned — automation stalls in the backlog. When the impact becomes undeniable, the budget follows. That’s the real beginning.
Friction You Will Meet on Day One
The moment the first automation workflow touches live operations, it collides with three unresolved forces: ambiguity, anxiety, and control. None are technical. All are structural.
The ambiguity lives in the data. Across CRM, ERP, and finance, “customer” can mean bill-to, ship-to, legal entity, or account manager. Each system encodes its truth in a different key. The bot fails not because the model misclassifies, but because the entity it predicts against doesn’t exist in one canonical form. PepsiCo’s AP rejection problem wasn’t modelled on invoice logic — it was rooted in fragmented vendor definitions between procurement and finance. The classifier worked only after shared schema alignment.
Anxiety lives in the executive layer. Manual rework is invisible until automation removes it — and when it does, the humans who’ve been stitching workflows together by memory feel exposed. Not replaced, not eliminated — unacknowledged. This is where resistance begins: not in obstruction, but in silent non-adoption. Companies didn’t launch with “bot coverage.” They launched with decision augmentation inside clearly scoped subprocesses. No roles erased, just time pressure lifted. That distinction bought trust.
Control is where friction calcifies. Internal audit, risk, and compliance teams flag AI workflows as untraceable unless decisions can be logged, versioned, and explained post-hoc. LLMs that summarise customer intent from inbound emails may lift SLA metrics, but unless the summary is linkable to the original text and prompt logic, it fails governance review. AI systems that rewrite processes must be able to surface their reasoning in operational language, not just logit curves.
The organisations that exit pilot mode do not resolve these frictions sequentially. They treat them as a single surface: data must be canonical, roles must be preserved or explicitly transformed, and decision logic must be inspectable. Anything less ensures the workflow remains a demo loop.
Capability Stack That Survives First Contact
No enterprise automates at scale without four primitives: clean event logs, a streaming backbone, cross-functional fluency, and a discretionary capital layer. Without these, even well-piloted use cases collapse at rollout.
The event log comes first. Not reports, not dashboards — logs. Time-stamped, queryable, complete. Every hand-off, status change, exception, and delay needs to be recorded. Most processes fail here: human interventions aren’t logged, system status codes are ambiguous, and latency hides in the gaps. Deutsche Telekom couldn’t rationalise its 800 HR processes until it rebuilt the instrumentation layer. What couldn’t be logged, couldn’t be streamlined.
Next: streaming. Events must flow in real-time across systems — ERP, CRM, WMS — so models can react without polling. This isn’t a technology preference; it’s a latency constraint. When the order confirmation, the stock allocation, and the shipping instruction all arrive minutes apart instead of hours, lead time compresses by default. Businesses’ waste reduction came not from the model architecture, but from synchronising sensor data with execution logic.
Then: talent fluency. Not headcount, not org charts — fluency. The process expert must read a BPMN map and understand why a feature is predictive. The ML engineer must know where the queue breaks down and why the exception path exists. The most effective teams speak across model weights and SLA violations without translation. McKinsey’s EBIT leaders all score high on this: hybrid teams that operate on a shared ontology of process and prediction.
Finally: discretionary capital. Not innovation funding. Not R&D budgets. A dedicated PoV allocation that bypasses the annual planning cycle and deploys in weeks. PepsiCo didn’t wait for budget year rollover to launch its classifier — they had infrastructure, logs, and a test set, so they built and deployed inside one fiscal quarter. That velocity is structural, not cultural.
This stack is not optional if you want to scale. One missing layer slows the entire loop. Every enterprise that reaches systemic impact in AI-driven automation solves for all four. Not eventually — up front.
Now we can see the bigger picture.
Before jumping into execution, it helps to step back and trace the pattern every high-impact automation project follows. This blueprint makes the loop visible — from pain points to sustained results.
With this in mind, let’s walk through how to apply it — one focused PoV at a time.
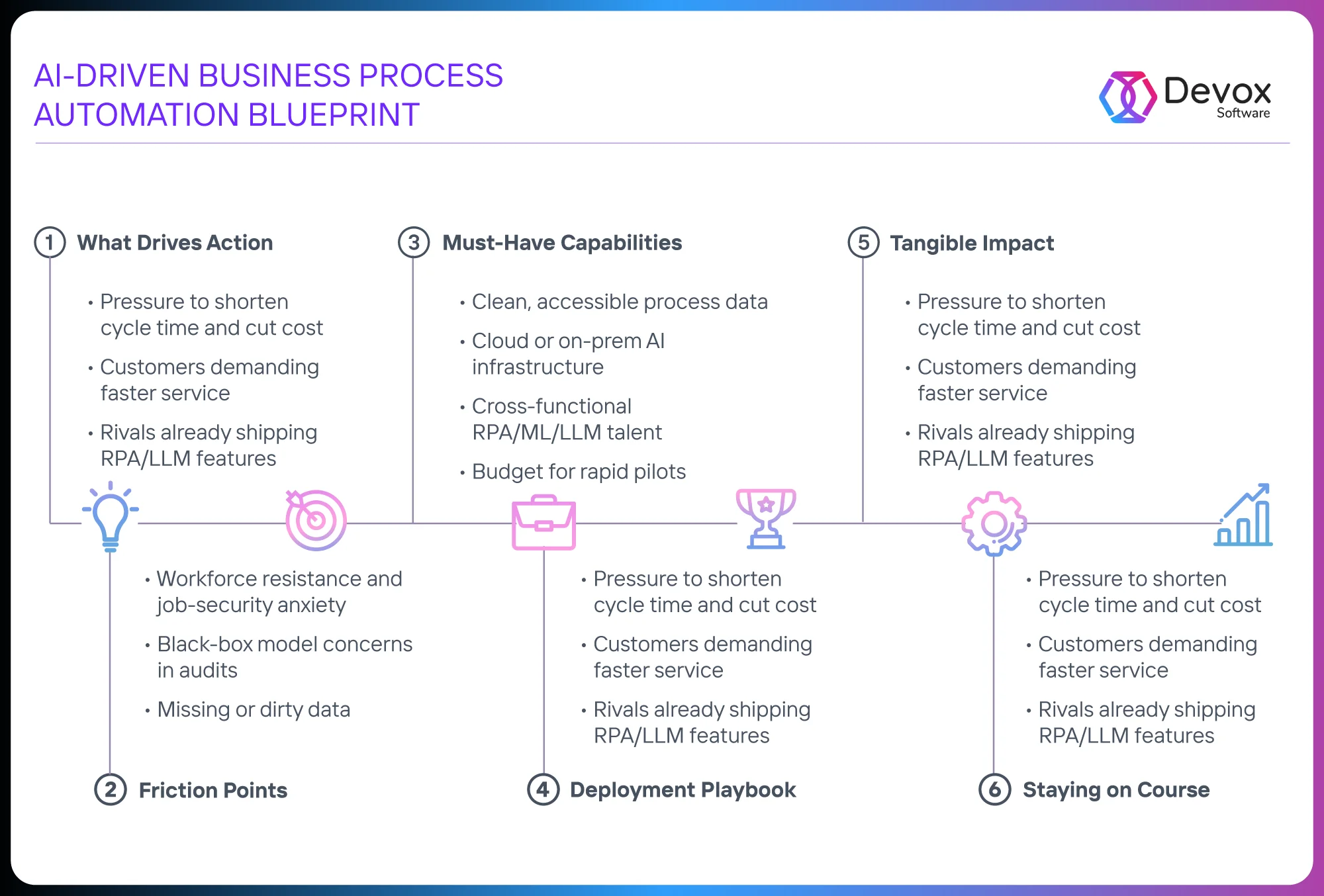
Deployment Playbook
There’s a proven loop, and every successful case follows it: map the process, identify the bottleneck, and run a focused six-week proof-of-value on that point alone, measure delta in minutes and dollars, and scale only when that delta survives CFO-level scrutiny.
Process mining makes this possible. It turns messy logs into a time-sequenced map of reality — every task, every wait-state, every loop. The team didn’t fix the SAP; they ran a targeted classifier to pre-validate incoming invoices. In six weeks, rejections dropped to 4%. This was not a strategic plan — it was a focused solution.
The same logic scaled Deutsche Telekom’s HR redesign. 800 processes, 20+ countries, thousands of conflicting rules. They didn’t start with systems. They started with Blueprint: a generative tool that inferred best-practice patterns from descriptive input. It did not replace process experts — it simply reduced the time and effort needed for iteration. They cleared 250 redesigns in months, not years. Each one followed a measurable improvement pattern: task latency down, exception loops closed, satisfaction scores up.
The key is scope. Each PoV targets a specific bottleneck — one rejection hotspot, one exception queue, one hand-off gap. If you cannot measure it by time, cost, or error rate, then it is not ready for automation. The PoV must resolve friction, not prove capability.
What you don’t do: automate the whole flow, launch from a slide, measure only by “bot count” or “model accuracy.” That is just showmanship — and it does not scale. AI succeeds or fails based on the operational impact it creates, and delta lives in knots, not maps.
The best teams treat every PoV like a balance sheet line. If it doesn’t move the number, it doesn’t move to production.
Tangible Impact Pattern
AI-driven automation delivers value not by removing tasks, but by reshaping the physics of the process itself. The pattern is structural:
Latency shortens. Predictive triggers replace scheduled batch logic. Exception loops closer to their origin. Processes execute in fewer steps with tighter time bounds. When every task emits telemetry, timing no longer depends on human memory or inbox load — it aligns to system throughput.
Variance decreases significantly. Statistical models help reduce deviation by detecting error conditions earlier. Classification layers catch malformed entries before they propagate; forecasting layers optimize flow at the level of probability, not rule. As variation narrows, first-pass yield rises — rework fades from the plan.
Working capital gets released. AI models forecasting demand, collections, or inventory levels compress the time between service and cash. Inventory buffers shrink. Days sales outstanding begin to contract. Capital trapped in overproduction or payment lag becomes deployable again.
Process visibility synchronises. Event logs across silos feed into a unified analytical layer. Every function sees the same live state; disputes fall in volume and duration. Cost of reconciliation declines. Work accelerates not because more people touch it, but because fewer have to ask what already happened.
Governance adapts in real time. Models retrain on live drift signals. Performance stabilises inside tolerance bands without quarterly review cycles. Feedback loops become infrastructure. Instead of waiting for deterioration, the process self-corrects as deviation begins to appear.
These outcomes don’t emerge from tool selection or technology stacks — they materialise when AI business process optimization treats the workflow as a living analytical surface. Where every interaction, delay, and exception emits traceable signals, optimization becomes continuous and measurable. AI succeeds not because it thinks, but because it lets the process feel where it falters.
Staying True Post-Launch
Automation rarely fails at launch. It fails when maintenance becomes optional — when telemetry stops working, and model drift goes unnoticed, and no one owns the variance. Sustained performance depends on three non-negotiables: event integrity, retraining autonomy, and single-point process ownership.
Reliable event logging is the foundation of it all. Each step, deviation, and delay must emit a signal into the system of record. Logs need to be complete, time-stamped, and tamper-proof. Without this, error conditions remain invisible, and the organisation returns to anecdotal triage. The system stops improving.
Automated retraining ensures that models adapt in real time without needing manual escalation. When error increases or distributions shift, retraining jobs trigger automatically, using live data and pre-approved pipelines. Accuracy remains inside tolerance bands without waiting for quarterly reviews or external data science cycles. This is how telemetry becomes actionable control.
Ownership consolidates execution. When multiple departments each control a piece of the workflow, no one is accountable for overall throughput. AI-driven processes remain stable only when one person owns full end-to-end accountability for performance across boundaries. This role governs trade-offs, arbitrates conflicts, and aligns incentives. Without it, automation fragments.
Governance must align upward. Companies that place AI responsibility at the CEO level report higher EBIT gains than those that assign it to innovation leads or isolated labs. McKinsey’s 2025 data shows this clearly: enterprise-level impact correlates with enterprise-level authority. When AI remains experimental, the results stay isolated. Where AI reports into operational command, process performance compounds.
Real automation does not make the process rigid — it makes it adaptable. Every input becomes observable, every deviation quantifiable, every improvement testable. Post-launch, the question isn’t “does it still work?” — the question is “how fast does it adapt?” Companies that can answer that question with code — not meetings — gain structural speed.
How Devox Software Makes This Process Faster, Safer, Smarter
Devox enters where most teams stall: signal without structure, ambition without alignment. Our AI Solution Accelerator™ codifies six years of delivery across real systems, broken workflows, and uneven data. It’s not a template. It’s a way to reduce friction in the steps that matter.
- We start with precision discovery. Using process mining and structured PoV framing, we isolate a single failure mode — one knot in the workflow that costs hours or margin. No blueprint until the bottleneck can be measured.
- We run rapid proofs of value. In six weeks, our stack deploys a focused ML, RPA, or LLM engine inside production-grade constraints. We do not measure model accuracy — we measure minutes saved, dollars recovered, and errors reduced.
- We deliver with execution-grade code. Every deployment is version-controlled, fully observable, retrainable, and production-safe. No vendor lock-in, no black-box scripts, no compliance blindspots. Auditors can step through every decision. Operations can govern drift with triggers, not decks.
- We build with cross-functional clarity. Every team we embed reads BPMN and speaks metrics. We work beside process owners, not around them. We write documentation that supports long-term operations.
- We close with scalable readiness. By the time we leave, the process emits events, the models self-monitor, and the ownership structure supports growth. Our goal isn’t automation at all — it’s resilience at speed.
Devox Software doesn’t pitch platforms. We clear paths. Fast enough to deliver results, safe enough to scale, and smart enough to stop when the value runs out.
Frequently Asked Questions
-
Do we need to “clean all the data” before launching AI, or is that just another way to stall?
True intelligence emerges not from pristine spreadsheets but from the messy trace of real operations — timestamps that fall on weekends, mis-typed IDs, exception flags that reveal where people step in. An AI pilot ingests those glitches and highlights them: it surfaces the loops nobody drew on the Visio, the hand-offs dragging work into the backlog. As each anomaly is corrected, the pipeline self-refines, event by event, so data quality evolves in lockstep with process clarity. The momentum from seeing actual bottlenecks collapse in days ignites the discipline to clean at scale, long before any hypothetical “perfect” data ever exists.
-
What are the core data requirements for effective BPA?
For process optimization AI to deliver value, it needs clean, time-stamped event logs, consistent primary keys across systems, and explicit ownership of exceptions. Without these, the AI chases noise or stalls in ambiguity. When the structure is sound, optimization becomes continuous — each loop shorter, each output smarter.
-
Can we accelerate AI adoption without a multi-year data overhaul?
Every month sunk into rewriting every database schema steals the spotlight from breakthroughs at the edges. A targeted pilot can run today on existing logs, catching timestamp drifts, exception flags, and user-triggered workarounds. That early glimpse reveals the handful of data pathways that carry the most drag, so you hardwire lightweight adapters around those points and feed live events straight into the model. Each sprint increases coverage, stitches in new sources, and sharpens signal quality. Within weeks, the CFO watches cycle times compress and variance shrink — exactly the kind of early result that validates enterprise AI process optimization without massive infrastructure changes. This dual-track method sprints past the glacial pace of “big bang” cleanses, turning imperfect data into actionable intelligence from day one.
-
What happens to my business process automation AI solution a year from now, when the system shifts, the team changes, or the process moves?
A year down the road, every tweak in your ERP, every shuffle on the operations team, and every tiny process pivot feeds straight into the same living pipeline that first powered your pilot. Every event remains time-stamped and immutable, and every decision is logged alongside the model version that made it. When a new exception pattern emerges, retraining kicks off automatically against the freshest traces, keeping predictions in line with reality. Turnover in the squad becomes a non-event — new engineers inherit a system where provenance lives in code commits and deployment manifests, not tribal knowledge. And as processes evolve, the same lightweight adapters you first spun up simply capture the new signals, folding them into dashboards and alerting you before any drift ever touches the balance sheet. This continuous feedback loop turns change from a threat into the very fuel that keeps your automation sharp.
-
What is the demand for home AI automation business, and does it influence enterprise automation strategies?
The consumer AI space, including smart homes, voice assistants, and personal automation, is growing rapidly, driven by convenience and energy savings. While enterprise and residential domains differ in scale, the rising demand for intelligent automation at home increases user comfort with AI-driven decision-making. For enterprise leaders, this signals a cultural shift: employees and customers increasingly expect the same intelligence and responsiveness in business systems that they now get in their homes.
-
How do we ensure explainability, logging, and policy alignment before launch?
Every decision carves its audit trail. Before a single prediction reaches production, each model call wraps itself in a structured metadata envelope — input payload, feature versions, model weights, policy rules, and user context all recorded in append-only logs. Those logs feed a real-time compliance layer that validates every inference against your governance playbook — data retention rules, bias checks, and access controls. An embedded explainability engine then translates black-box outputs into human-readable rationales, linking each recommended action back to the exact features and thresholds that drove it. All components run under consistent versioned pipelines, so when an auditor demands proof, you can replay any transaction at any moment, with complete fidelity to the policies and data definitions that governed it. Continuous monitoring flags any deviation immediately, turning compliance into an automatic heartbeat rather than a manual afterthought.
This level of traceability is also how AI and automation help small businesses build trust in automation early, proving that decisions are not only fast and efficient but also explainable, auditable, and safe from day one.
-
Can we launch an AI-powered MVP without overhauling our entire system landscape?
AI-powered automation for businesses can spring to life atop your existing architecture through modular adapters and lightweight inference layers. Smart adapters sit beside legacy services, streaming just the critical event streams into your model without disturbing core transactions. In parallel, a containerized inference endpoint lives in its own namespace, consuming those events, issuing decisions, and logging every call. As the proof of value unfolds, you extend each adapter only when its signal proves essential, so the system grows organically, feature by feature, rather than collapsing under a simultaneous “big bang” refactor. The result: a living MVP that delivers intelligent automation today and coexists with tomorrow’s sweeping overhaul, each evolution building on a foundation already proven in production.


